Agent Skills: Architecture, Implementation, and the Future of Composable AI Agent Knowledge
A deep technical analysis of the SKILL.md specification, progressive disclosure patterns, and how agent skills fundamentally reshape LLM-based agent architectures.
1. The Context Window Problem: Why Skills Exist
Every production AI agent faces a fundamental engineering constraint: the context window is finite, expensive, and shared across every turn of conversation. Consider an agent equipped with dozens of specialized workflows — CI/CD pipelines, security review checklists, documentation formatters, data analysis routines, migration helpers. The naive architecture loads every instruction set into the system prompt at initialization. The token arithmetic is sobering:
- Even a modest library of 30 workflows at ~5,000 tokens each consumes roughly 150,000 tokens before the user says a word
- That budget is spent identically whether the user triggers a complex deployment or simply renames a variable
- On frontier models priced around $10 per million input tokens, the system prompt alone costs $1.50 per request
- Prefill latency grows linearly with input length — at 150K tokens, the user is waiting seconds just for the model to process instructions it may never use
The solution draws on a concept familiar to operating-system engineers: demand paging. Rather than loading everything up front, the agent boots with a lightweight index of skill metadata — names and one-line descriptions totaling roughly 3,000 tokens — and pulls full instruction sets into context only when a task actually requires them.
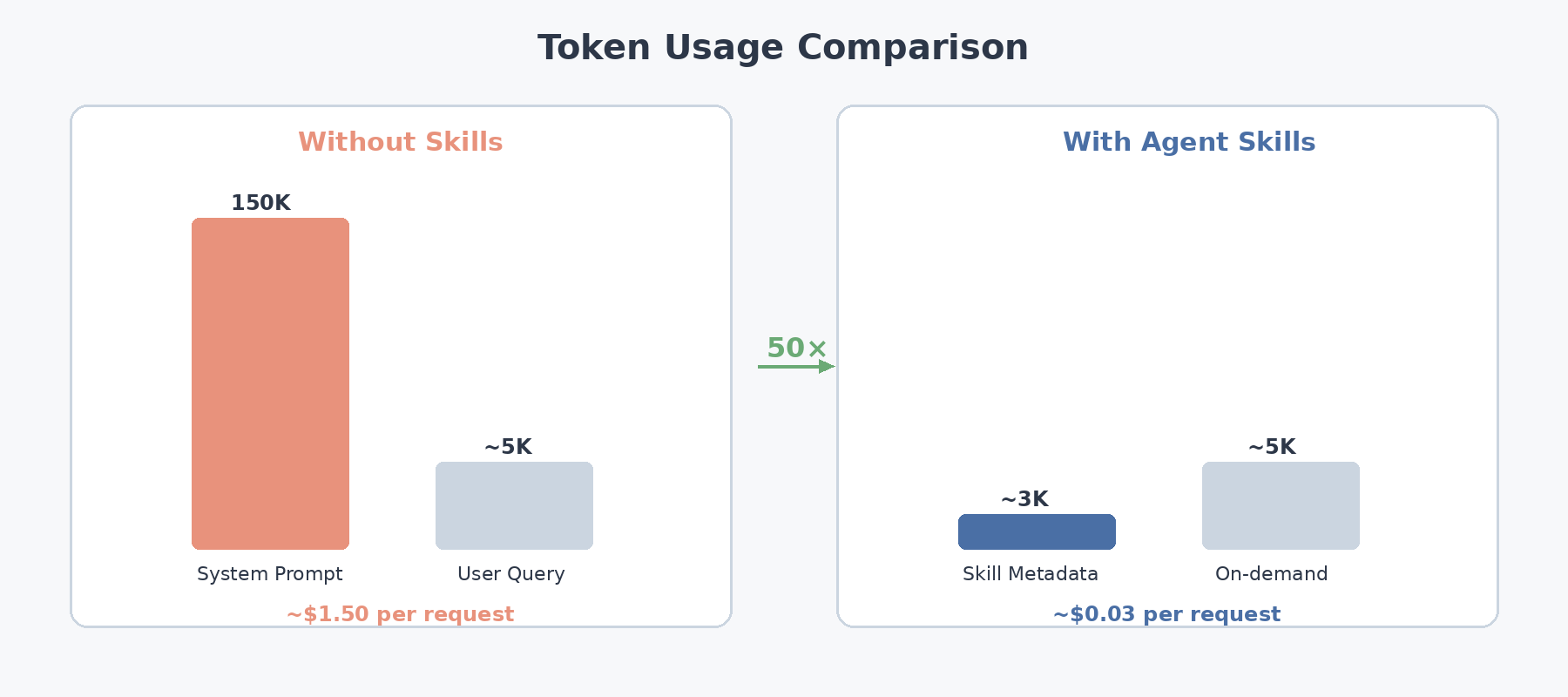
The practical result is approximately a 50× reduction in startup token cost, with per-request averages dropping proportionally since most interactions activate only one or two skills at a time.
2. The SKILL.md Specification: Anatomy of a Skill
When Anthropic published the SKILL.md specification as an open standard in late 2025, it deliberately chose the lowest-friction format possible: a Markdown file with YAML frontmatter and a directory convention. That simplicity drove rapid cross-platform adoption — within a few months, implementations appeared in OpenAI Codex, Google Gemini CLI, GitHub Copilot, Cursor, JetBrains Junie, and dozens of other agent-oriented products.
2.1 File Structure
A skill lives in a directory with a defined structure:
my-skill/
├── SKILL.md # Required: frontmatter + instructions
├── scripts/ # Optional: executable scripts
│ ├── validate.py
│ └── transform.sh
├── references/ # Optional: supplementary docs
│ ├── style-guide.md
│ └── api-schema.json
└── assets/ # Optional: static files
└── template.html
2.2 SKILL.md Format
The file starts with YAML frontmatter (required fields: name and description) followed by a Markdown body with the actual instructions:
---
name: code-review-security
description: >
Performs security-focused code review. Identifies injection vulnerabilities,
auth bypasses, secrets exposure, and insecure deserialization patterns.
Use when reviewing PRs or auditing codebases for security issues.
license: MIT
compatibility:
- claude
- codex
- gemini-cli
allowed-tools:
- read_file
- grep
- bash(read-only)
metadata:
author: security-team
version: 2.1.0
tags: [security, review, OWASP]
---
# Security Code Review Skill
## Workflow
1. Scan all changed files for security-sensitive patterns
2. Check for hardcoded secrets using regex patterns
3. Identify SQL injection vectors in database queries
4. Review authentication and authorization logic
5. Flag insecure deserialization or eval() usage
6. Generate findings report with severity ratings
## Best Practices
- Always check for both direct and indirect injection paths
- Review dependency versions against known CVE databases
- Flag any use of `eval()`, `exec()`, or `subprocess.shell=True`
## Edge Cases
- Template injection in Jinja2/Mako templates
- GraphQL query depth attacks
- SSRF through URL parsing inconsistencies
2.3 Building a Skill Registry in Python
Here’s a practical implementation of a skill discovery and loading system:
import os
import yaml
import hashlib
from dataclasses import dataclass, field
from pathlib import Path
from typing import Optional
@dataclass
class SkillMetadata:
"""Tier 1 representation: only what's needed for the system prompt."""
name: str
description: str
path: Path
token_estimate: int = 0
allowed_tools: list[str] = field(default_factory=list)
content_hash: str = ""
def to_system_prompt_entry(self) -> str:
"""Generate the ~100-token entry for the system prompt."""
return f"- **{self.name}**: {self.description}"
@dataclass
class LoadedSkill:
"""Tier 2 representation: full SKILL.md body loaded into context."""
metadata: SkillMetadata
body: str # Markdown body after frontmatter
references: dict[str, str] = field(default_factory=dict)
scripts: dict[str, str] = field(default_factory=dict)
class SkillRegistry:
"""
Manages skill discovery, registration, and progressive loading.
Implements the three-tier disclosure pattern from the SKILL.md spec.
"""
DISCOVERY_PATHS = [
".claude/skills", # Claude-specific
".agents/skills", # Cross-platform convention
".cursor/skills", # Cursor-specific
]
GLOBAL_PATH = Path.home() / ".claude" / "skills"
def __init__(self):
self._registry: dict[str, SkillMetadata] = {}
self._loaded: dict[str, LoadedSkill] = {}
self._activation_log: list[dict] = []
def discover(self, project_root: str = ".") -> list[SkillMetadata]:
"""
Stage 0: Scan all skill sources and register metadata.
Only parses YAML frontmatter — never reads the full body.
"""
sources = [
("project", self._scan_project_skills(project_root)),
("global", self._scan_directory(self.GLOBAL_PATH)),
]
for source_type, skills in sources:
for skill in skills:
self._registry[skill.name] = skill
print(f"[discover] Registered '{skill.name}' from {source_type}")
return list(self._registry.values())
def _scan_project_skills(self, project_root: str) -> list[SkillMetadata]:
"""Scan project-level skill directories."""
skills = []
for rel_path in self.DISCOVERY_PATHS:
skills_dir = Path(project_root) / rel_path
skills.extend(self._scan_directory(skills_dir))
return skills
def _scan_directory(self, directory: Path) -> list[SkillMetadata]:
"""Scan a directory for SKILL.md files and extract frontmatter only."""
skills = []
if not directory.exists():
return skills
for skill_dir in directory.iterdir():
skill_file = skill_dir / "SKILL.md" if skill_dir.is_dir() else None
if skill_file and skill_file.exists():
metadata = self._parse_frontmatter(skill_file)
if metadata:
skills.append(metadata)
return skills
def _parse_frontmatter(self, path: Path) -> Optional[SkillMetadata]:
"""Extract only the YAML frontmatter from a SKILL.md file."""
content = path.read_text(encoding="utf-8")
if not content.startswith("---"):
return None
# Find the closing --- of the frontmatter
end_idx = content.index("---", 3)
frontmatter_str = content[3:end_idx].strip()
fm = yaml.safe_load(frontmatter_str)
return SkillMetadata(
name=fm["name"],
description=fm["description"],
path=path,
token_estimate=len(frontmatter_str.split()) * 2, # rough estimate
allowed_tools=fm.get("allowed-tools", []),
content_hash=hashlib.sha256(content.encode()).hexdigest()[:12],
)
def build_system_prompt_block(self) -> str:
"""
Tier 1: Generate the skills block for the system prompt.
This is injected once at startup and stays in every request.
"""
lines = ["## Available Skills\n"]
total_tokens = 0
for skill in self._registry.values():
entry = skill.to_system_prompt_entry()
lines.append(entry)
total_tokens += len(entry.split()) * 1.3 # rough token estimate
lines.append(f"\n_({len(self._registry)} skills, ~{int(total_tokens)} tokens)_")
return "\n".join(lines)
def activate(self, skill_name: str) -> LoadedSkill:
"""
Tier 2: Load the full SKILL.md body into context.
Called when the LLM selects a skill based on user query.
"""
if skill_name in self._loaded:
return self._loaded[skill_name]
metadata = self._registry.get(skill_name)
if not metadata:
raise KeyError(f"Skill '{skill_name}' not found in registry")
# Read full file and split frontmatter from body
content = metadata.path.read_text(encoding="utf-8")
parts = content.split("---", 2)
body = parts[2].strip() if len(parts) > 2 else ""
skill = LoadedSkill(metadata=metadata, body=body)
self._loaded[skill_name] = skill
self._activation_log.append({
"skill": skill_name,
"action": "activate",
"body_tokens": len(body.split()) * 1.3,
})
return skill
def load_reference(self, skill_name: str, ref_path: str) -> str:
"""
Tier 3: Load a reference file on-demand during execution.
"""
skill = self._loaded.get(skill_name)
if not skill:
raise RuntimeError(f"Skill '{skill_name}' must be activated first")
ref_file = skill.metadata.path.parent / ref_path
if not ref_file.exists():
raise FileNotFoundError(f"Reference '{ref_path}' not found")
content = ref_file.read_text(encoding="utf-8")
skill.references[ref_path] = content
return content
def deactivate(self, skill_name: str) -> None:
"""
Stage 6: Unload skill from context after execution.
Frees context window tokens for subsequent operations.
"""
if skill_name in self._loaded:
del self._loaded[skill_name]
self._activation_log.append({
"skill": skill_name,
"action": "deactivate",
})
def get_context_usage(self) -> dict:
"""Report current context token usage from loaded skills."""
total = 0
breakdown = {}
for name, skill in self._loaded.items():
body_tokens = len(skill.body.split()) * 1.3
ref_tokens = sum(len(v.split()) * 1.3 for v in skill.references.values())
skill_total = body_tokens + ref_tokens
breakdown[name] = int(skill_total)
total += skill_total
return {"total_tokens": int(total), "breakdown": breakdown}
Usage:
# Initialize and discover skills
registry = SkillRegistry()
registry.discover(project_root="/home/user/my-project")
# Tier 1: Build system prompt (runs once at agent startup)
system_prompt = f"""You are a development assistant.
{registry.build_system_prompt_block()}
When a user request matches a skill, activate it before responding.
"""
# Tier 2: Activate when LLM selects a skill
skill = registry.activate("code-review-security")
# Inject skill.body into the conversation context
# Tier 3: Load references on-demand
style_guide = registry.load_reference("code-review-security", "references/style-guide.md")
# After execution, free context
registry.deactivate("code-review-security")
print(registry.get_context_usage()) # {"total_tokens": 0, "breakdown": {}}
3. The Agent Skills Lifecycle: From Discovery to Dehydration
The skill lifecycle is a 7-stage pipeline. Understanding each stage is critical for building agents that use skills efficiently.
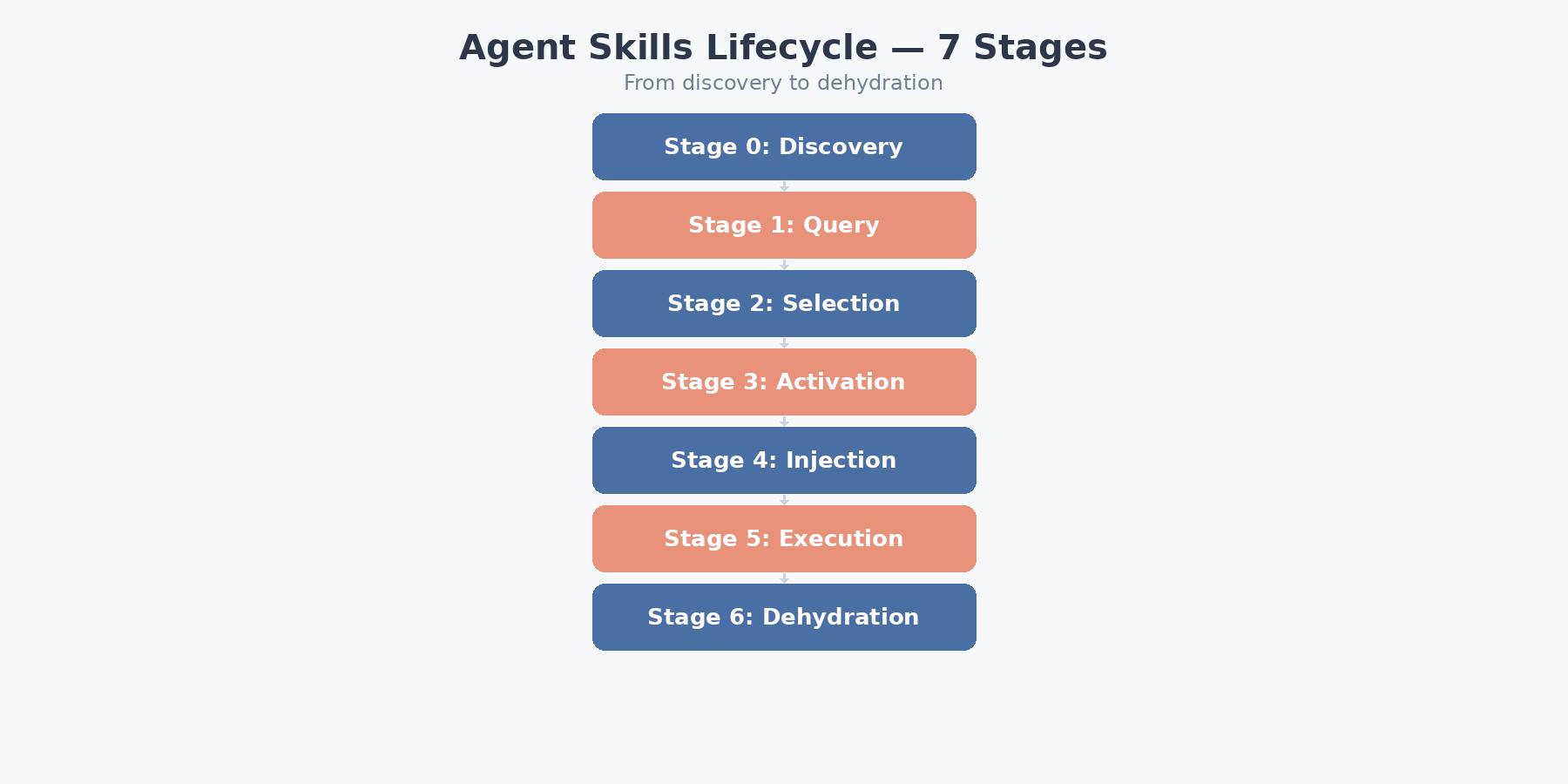
Stage 0: Skills Discovery
The runtime scans multiple sources on startup:
| Source | Path / Mechanism | Scope |
|---|---|---|
| Project | .agents/skills/, .claude/skills/ |
Local to repo |
| Global | ~/.claude/skills/ |
User-wide |
| Bundled | Ships with platform | Platform-wide |
| Plugins | Third-party packages | Installed packages |
| Community | Marketplace / repos | On-demand install |
Only the YAML frontmatter is parsed. The body is never read at this stage.
Stage 1–2: Query → Skill Selection
When a user query arrives, the model evaluates it against the skill descriptions already present in the system prompt and decides which skill, if any, to activate. There is no retrieval step, no embedding lookup, and no external classifier in the routing path — selection is a byproduct of the model’s own forward pass. This design choice has a profound implication: the description field in the YAML frontmatter is the single highest-leverage line in any skill file, because it is the only text the model sees when making its selection decision.
class SkillSelector:
"""
Demonstrates how skill selection works in the agent loop.
The LLM does the actual selection; this class manages the interaction.
"""
def __init__(self, registry: SkillRegistry, llm_client):
self.registry = registry
self.llm = llm_client
def select_skill(self, user_query: str) -> Optional[str]:
"""
Ask the LLM which skill (if any) matches the user query.
Returns skill name or None.
"""
skills_block = self.registry.build_system_prompt_block()
selection_prompt = f"""Given the user query below, determine which skill
(if any) should be activated. Respond with ONLY the skill name, or "none".
Available skills:
{skills_block}
User query: {user_query}
Selected skill:"""
response = self.llm.complete(selection_prompt, max_tokens=50)
skill_name = response.strip().lower()
if skill_name == "none" or skill_name not in self.registry._registry:
return None
return skill_name
def execute_with_skill(self, user_query: str) -> str:
"""Full agent loop: select skill → activate → execute → deactivate."""
skill_name = self.select_skill(user_query)
if skill_name:
# Tier 2: Load full instructions
skill = self.registry.activate(skill_name)
context_injection = f"""
[SKILL ACTIVATED: {skill_name}]
{skill.body}
[END SKILL]
"""
else:
context_injection = ""
# Execute with enriched context
response = self.llm.chat(
system=f"You are an assistant. {context_injection}",
user=user_query,
)
# Dehydrate: unload skill after use
if skill_name:
self.registry.deactivate(skill_name)
return response
Stages 3–4: Activation and Context Injection
When a skill is selected, loading happens in three progressive stages — this is the core of the “progressive disclosure” pattern:
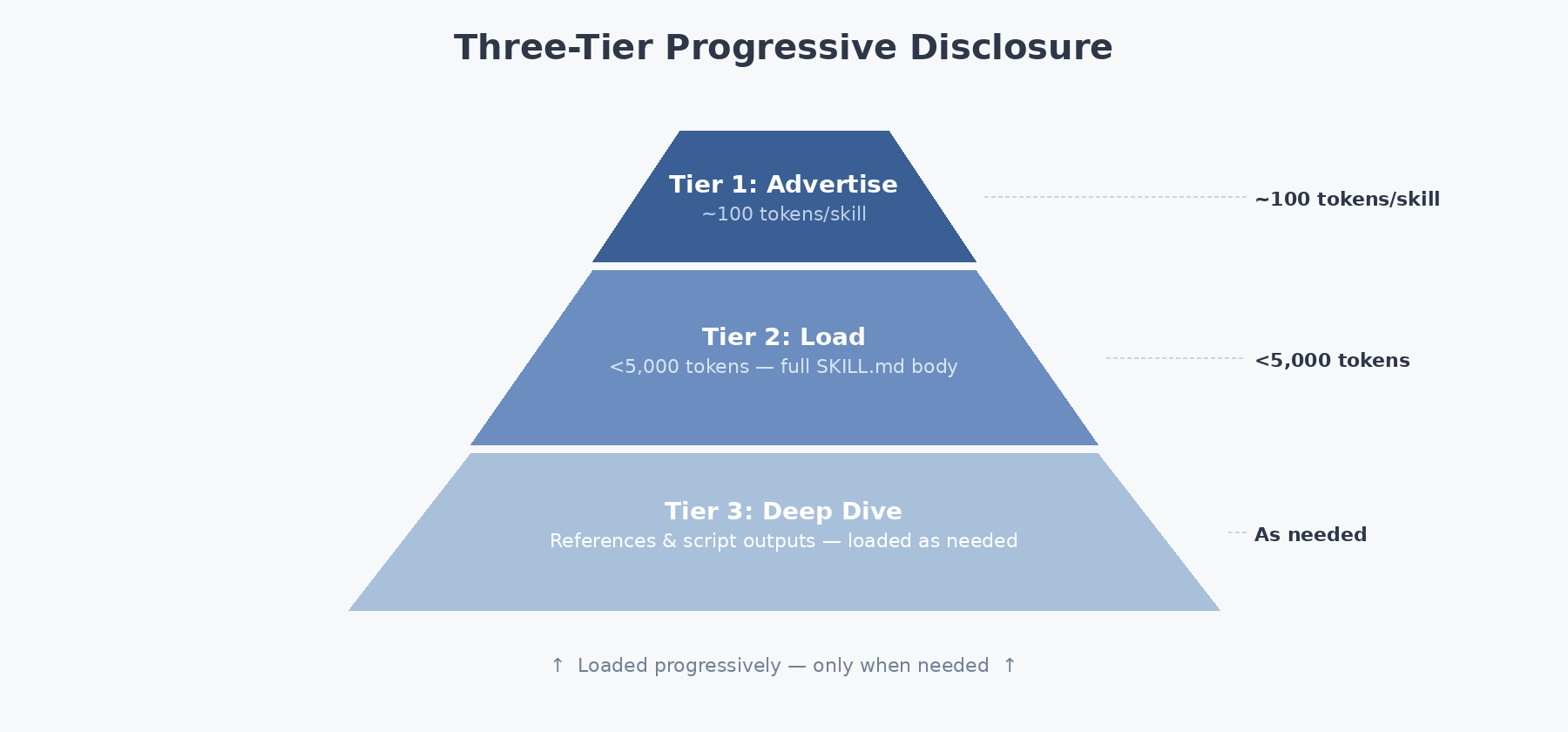
Tier 1 — Advertise (~100 tokens per skill): The runtime parses only the YAML frontmatter from each SKILL.md and injects a compact name-plus-description entry into the system prompt. This is the fixed per-skill cost that persists across every request: N_skills × ~100 tokens.
Tier 2 — Load (budget target: <5,000 tokens): Once the model identifies a relevant skill, the full Markdown body is read into context — step-by-step workflows, domain-specific best practices, known edge cases. The specification guidelines suggest capping this body at 500 lines to keep Tier 2 costs predictable.
Tier 3 — Deep Dive (on-demand, unbounded): Supplementary reference documents and executable scripts are loaded only during active skill execution. A key architectural detail: scripts run in a subprocess, and only their stdout enters the model’s context — the source code never does. A 200-line validation script that emits 10 lines of structured output therefore costs 10 lines of context, not 200.
import subprocess
import json
class SkillExecutor:
"""Handles Tier 3 deep-dive: running skill scripts and collecting output."""
def __init__(self, skill: LoadedSkill):
self.skill = skill
self.script_outputs: dict[str, str] = {}
def run_script(
self,
script_name: str,
args: list[str] = None,
timeout: int = 30,
) -> str:
"""
Execute a skill script and return only its output.
The script source code never enters the LLM context.
"""
script_path = self.skill.metadata.path.parent / "scripts" / script_name
if not script_path.exists():
raise FileNotFoundError(f"Script '{script_name}' not found")
# Determine interpreter from extension
ext = script_path.suffix
interpreter = {
".py": ["python3"],
".sh": ["bash"],
".js": ["node"],
}.get(ext, ["bash"])
cmd = interpreter + [str(script_path)] + (args or [])
try:
result = subprocess.run(
cmd,
capture_output=True,
text=True,
timeout=timeout,
cwd=str(script_path.parent),
)
output = result.stdout.strip()
if result.returncode != 0:
output += f"\n[STDERR]: {result.stderr.strip()}"
except subprocess.TimeoutExpired:
output = f"[ERROR] Script timed out after {timeout}s"
self.script_outputs[script_name] = output
return output
def get_context_payload(self) -> str:
"""
Build the context injection payload combining the skill body,
loaded references, and script outputs.
"""
sections = [f"# Skill: {self.skill.metadata.name}\n", self.skill.body]
if self.skill.references:
sections.append("\n## Loaded References\n")
for ref_name, content in self.skill.references.items():
sections.append(f"### {ref_name}\n{content}\n")
if self.script_outputs:
sections.append("\n## Script Outputs\n")
for script_name, output in self.script_outputs.items():
sections.append(f"### {script_name}\n```\n{output}\n```\n")
return "\n".join(sections)
Stages 5–6: Execution and Dehydration
The enriched agent executes using its normal toolset (file operations, bash, MCP servers, web search). After producing output, the skill is dehydrated — unloaded from context to free tokens.
For multi-step tasks, the agent follows a load-execute-unload-repeat pattern: one skill at a time, sequential activation. This keeps context usage proportional to the current step, not the total workflow.
class MultiStepSkillPipeline:
"""
Demonstrates multi-step dehydration: load one skill at a time,
execute, unload, then move to the next step.
"""
def __init__(self, registry: SkillRegistry, llm_client):
self.registry = registry
self.llm = llm_client
def execute_pipeline(self, steps: list[dict]) -> list[str]:
"""
Execute a sequence of skill-powered steps.
Each step: {"skill": "skill-name", "task": "description"}
"""
results = []
accumulated_context = [] # Carry forward key results, not full skills
for i, step in enumerate(steps):
print(f"\n--- Step {i+1}: {step['skill']} ---")
# Activate skill for this step
skill = self.registry.activate(step["skill"])
executor = SkillExecutor(skill)
# Build context with skill instructions + previous results summary
context = executor.get_context_payload()
if accumulated_context:
context += "\n## Previous Results\n" + "\n".join(accumulated_context)
# Execute
response = self.llm.chat(
system=f"Follow the skill instructions precisely.\n{context}",
user=step["task"],
)
results.append(response)
# Carry forward a compressed summary, not the full response
summary = self.llm.complete(
f"Summarize this result in 2-3 sentences:\n{response}",
max_tokens=100,
)
accumulated_context.append(f"Step {i+1} ({step['skill']}): {summary}")
# Dehydrate: unload the skill
self.registry.deactivate(step["skill"])
print(f"Context after dehydration: {self.registry.get_context_usage()}")
return results
# Usage:
pipeline_steps = [
{"skill": "code-review-security", "task": "Review auth.py for vulnerabilities"},
{"skill": "deploy-pipeline", "task": "Deploy the reviewed code to staging"},
{"skill": "test-runner", "task": "Run integration tests against staging"},
]
# results = pipeline.execute_pipeline(pipeline_steps)
4. Tools vs. Skills: A Critical Architectural Distinction
This is arguably the most important conceptual insight in the entire spec. Developers often conflate tools and skills, but they serve fundamentally different roles in the agent architecture.
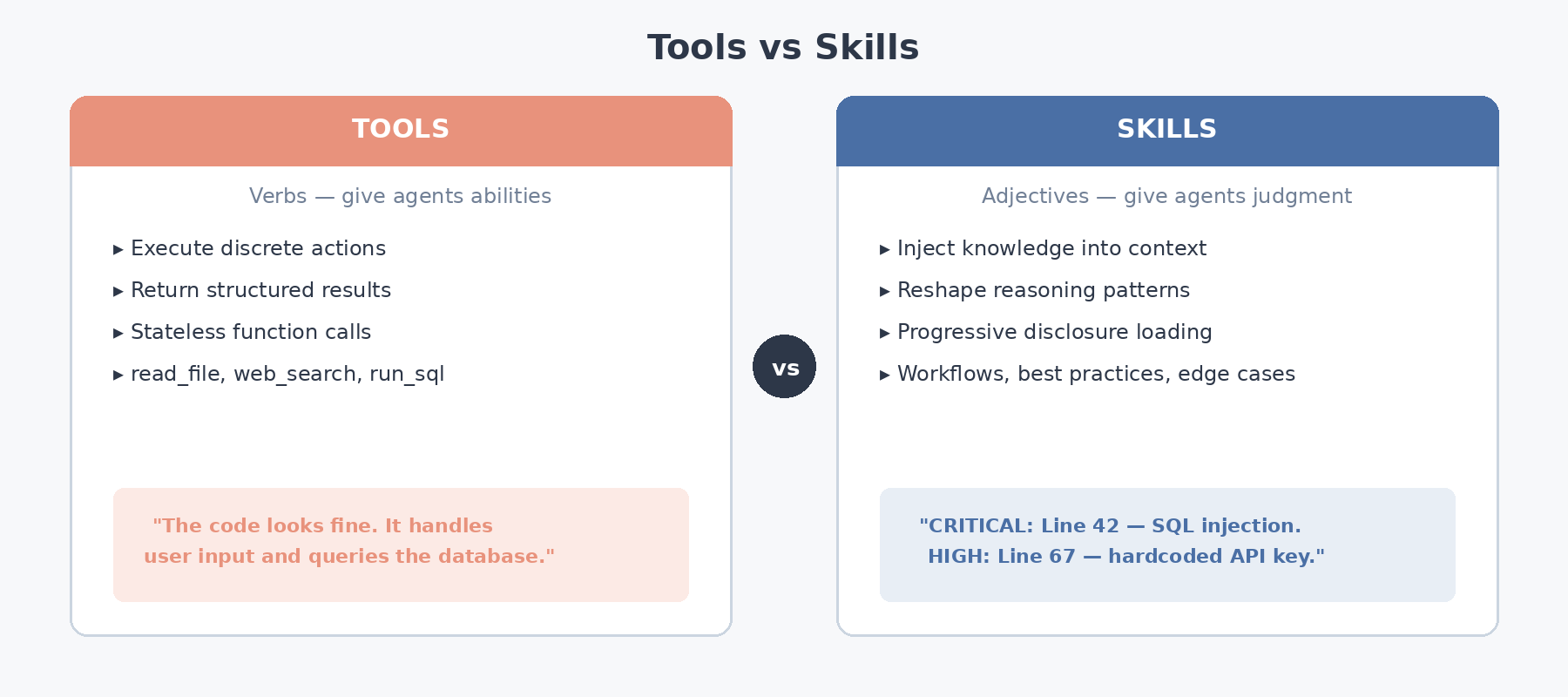
Tools: Execute Actions, Return Results
# A tool is a callable that does one thing and returns data
def read_file(path: str) -> str:
"""Tool: discrete action, immediate result."""
with open(path) as f:
return f.read()
def web_search(query: str) -> list[dict]:
"""Tool: discrete action, immediate result."""
# ... call search API ...
return [{"title": "...", "url": "...", "snippet": "..."}]
def run_sql(query: str, connection_string: str) -> list[dict]:
"""Tool: discrete action, immediate result."""
# ... execute query, return rows ...
return [{"id": 1, "name": "Alice"}]
Tools function as verbs in the agent’s vocabulary — each one grants a discrete capability: reading a file, querying a search index, executing SQL. The interaction pattern is always call → result → move on.
Skills: Inject Knowledge, Reshape Reasoning
Skills, by contrast, operate more like adjectives — they reshape the agent’s reasoning posture rather than granting a new action. Loading a security-review skill doesn’t merely let the agent scan for vulnerabilities; it equips the agent with structured judgment: which vulnerability classes to prioritize, what order to inspect them in, and how to calibrate severity ratings.
# Before skill activation: generic response
# User: "Review this code"
# Agent: "The code looks fine. It handles user input and queries the database."
# After security-review skill activation:
# The agent's context now contains:
# - "Always check for SQL injection in parameterized queries"
# - "Flag any use of eval(), exec(), or subprocess with shell=True"
# - "Review auth logic for IDOR vulnerabilities"
# - "Check for hardcoded secrets using regex: r'(?i)(api[_-]?key|secret|password)\s*=\s*[\"'][^\"']+'"
# User: "Review this code"
# Agent: "CRITICAL: Line 42 uses string formatting in SQL query — SQL injection risk.
# HIGH: Line 67 contains a hardcoded API key.
# MEDIUM: Line 89 uses eval() on user input — arbitrary code execution."
The key insight: Tools give agents abilities. Skills give agents judgment.
from enum import Enum
class ComponentType(Enum):
TOOL = "tool"
SKILL = "skill"
class AgentComponent:
"""Demonstrates the architectural difference between tools and skills."""
def __init__(self, name: str, component_type: ComponentType):
self.name = name
self.type = component_type
class Tool(AgentComponent):
"""Executes a discrete action and returns a result."""
def __init__(self, name: str, func: callable):
super().__init__(name, ComponentType.TOOL)
self.func = func
def execute(self, **kwargs) -> str:
return self.func(**kwargs)
class Skill(AgentComponent):
"""Injects knowledge into the agent's context."""
def __init__(self, name: str, instructions: str, allowed_tools: list[str]):
super().__init__(name, ComponentType.SKILL)
self.instructions = instructions
self.allowed_tools = allowed_tools # Skills scope which tools can be used
def inject(self, current_context: str) -> str:
"""Reshape the agent's context with skill knowledge."""
return f"""{current_context}
[SKILL: {self.name}]
{self.instructions}
[ALLOWED TOOLS: {', '.join(self.allowed_tools)}]
[END SKILL]"""
5. Skills + MCP: The Complementary Architecture
A common misconception is that Skills and MCP (Model Context Protocol) overlap or compete for the same architectural niche. In practice, they occupy distinct layers of the agent stack and are designed to evolve independently. Getting this separation right is one of the more consequential decisions in production agent design.
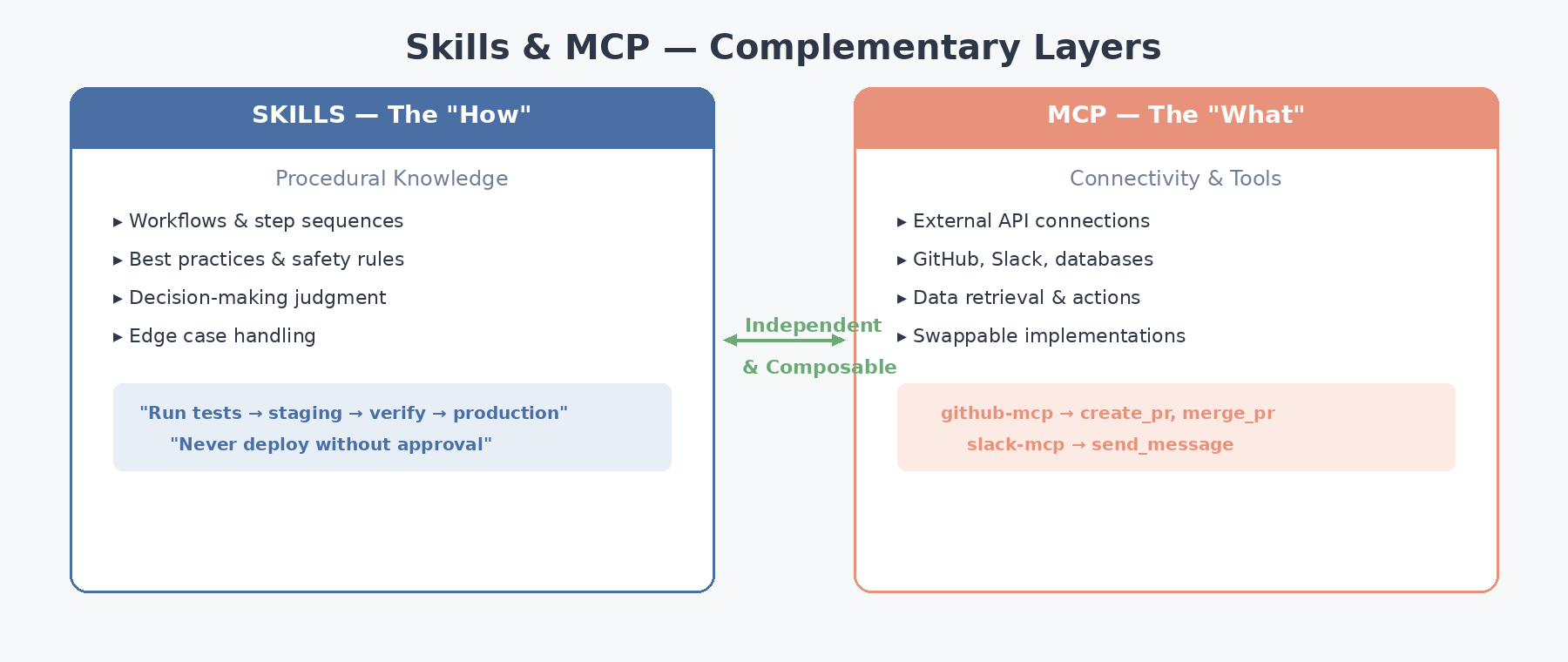
The Separation of Concerns
| Layer | Purpose | Provides | Example |
|---|---|---|---|
| Skills | Procedural knowledge | How to do things | “Run tests before deploying. Check staging health. Rollback on failure.” |
| MCP | Connectivity | What services to use | GitHub API, Slack, database connections |
A skill might instruct the agent to:
- Use a specific MCP server (
github-mcp) to create a PR - Define how to interpret its outputs (parse review comments)
- Enforce safety checks before destructive operations (require approval before merge)
Because the layers have no shared state, you can replace an MCP server (migrating from GitHub to GitLab, for example) without editing a single skill file, and conversely revise skill workflows without touching any MCP configuration. This independence is what makes the architecture genuinely composable.
from dataclasses import dataclass
from typing import Protocol
# --- MCP Layer: Connectivity ---
class MCPServer(Protocol):
"""Protocol for MCP server implementations."""
def list_tools(self) -> list[dict]: ...
def call_tool(self, name: str, args: dict) -> dict: ...
@dataclass
class GitHubMCPServer:
"""MCP server providing GitHub API access."""
token: str
base_url: str = "https://api.github.com"
def list_tools(self) -> list[dict]:
return [
{"name": "create_pr", "description": "Create a pull request"},
{"name": "list_reviews", "description": "List PR reviews"},
{"name": "merge_pr", "description": "Merge a pull request"},
]
def call_tool(self, name: str, args: dict) -> dict:
# Implementation calls GitHub REST API
...
@dataclass
class GitLabMCPServer:
"""MCP server providing GitLab API access — swappable with GitHub."""
token: str
base_url: str = "https://gitlab.com/api/v4"
def list_tools(self) -> list[dict]:
return [
{"name": "create_pr", "description": "Create a merge request"},
{"name": "list_reviews", "description": "List MR reviews"},
{"name": "merge_pr", "description": "Merge a merge request"},
]
def call_tool(self, name: str, args: dict) -> dict:
# Implementation calls GitLab REST API
...
# --- Skills Layer: Procedural Knowledge ---
DEPLOY_SKILL_INSTRUCTIONS = """
# Deploy Pipeline Skill
## Workflow
1. Run `test-runner` skill first — deploy only if all tests pass
2. Create a PR with the deployment changes
3. Wait for at least 1 approving review
4. Deploy to staging environment
5. Run smoke tests against staging
6. If smoke tests pass, merge PR and deploy to production
7. If smoke tests fail, rollback staging and comment failure details on PR
## Safety Checks
- NEVER deploy directly to production without staging verification
- NEVER merge without at least 1 approving review
- Always create a rollback plan before production deployment
## Tool Permissions
- Allowed: create_pr, list_reviews, merge_pr, bash, read_file
- Forbidden: delete_branch (must be manual)
"""
class AgenticStack:
"""
Demonstrates the full agentic stack:
Skills (how) + MCP (what) + LLM (execution)
"""
def __init__(self, mcp_server: MCPServer, skill_registry: SkillRegistry):
self.mcp = mcp_server
self.skills = skill_registry
def deploy(self, branch: str):
"""
The skill provides the WORKFLOW (how to deploy).
MCP provides the CONNECTIVITY (how to talk to GitHub/GitLab).
The LLM follows skill instructions and calls MCP tools.
"""
# Skill says: "Run tests first"
# MCP provides: the test runner tool
# LLM: orchestrates both
# Swap mcp_server from GitHubMCPServer to GitLabMCPServer
# and this method doesn't change at all — the skill instructions
# remain identical because they reference abstract tool names,
# not GitHub-specific endpoints.
pass
The Agentic Stack
The full architecture stacks four layers, each with a clear responsibility:

┌─────────────────────────────────┐
│ Agent Runtime │ ← Orchestration, UI, state management
├─────────────────────────────────┤
│ Skills │ ← The "how": workflows, best practices
├─────────────────────────────────┤
│ MCP │ ← The "what": tools, data, external APIs
├─────────────────────────────────┤
│ LLM + Execution │ ← Model inference, bash, filesystem
└─────────────────────────────────┘
6. Writing High-Quality Skills: Practical Guide
The quality of your skills directly determines agent performance. Here’s a production-grade skill with all the patterns that matter:
SKILL_TEMPLATE = '''---
name: {name}
description: >
{description}
Trigger conditions: {triggers}
license: MIT
compatibility:
- claude
- codex
- gemini-cli
- cursor
allowed-tools:
{allowed_tools}
metadata:
author: {author}
version: {version}
tags: [{tags}]
---
# {title}
## Overview
{overview}
## Workflow
{workflow_steps}
## Best Practices
{best_practices}
## Edge Cases
{edge_cases}
## Output Format
{output_format}
'''
def generate_skill(
name: str,
description: str,
triggers: str,
workflow_steps: list[str],
best_practices: list[str],
edge_cases: list[str],
allowed_tools: list[str],
output_format: str = "Markdown report",
author: str = "team",
version: str = "1.0.0",
tags: list[str] = None,
) -> str:
"""Generate a well-structured SKILL.md file from parameters."""
workflow = "\n".join(f"{i+1}. {step}" for i, step in enumerate(workflow_steps))
practices = "\n".join(f"- {p}" for p in best_practices)
edges = "\n".join(f"- {e}" for e in edge_cases)
tools_yaml = "\n ".join(f"- {t}" for t in allowed_tools)
tag_str = ", ".join(tags or [name])
return SKILL_TEMPLATE.format(
name=name,
description=description,
triggers=triggers,
title=name.replace("-", " ").title(),
overview=description,
workflow_steps=workflow,
best_practices=practices,
edge_cases=edges,
allowed_tools=tools_yaml,
output_format=output_format,
author=author,
version=version,
tags=tag_str,
)
# Example: Generate a database migration skill
migration_skill = generate_skill(
name="db-migration",
description="Safely execute database schema migrations with rollback support.",
triggers="User mentions 'migration', 'schema change', 'alter table', 'add column'.",
workflow_steps=[
"Parse the migration file and identify all schema changes",
"Generate a rollback script for each change",
"Run migrations against a test database first",
"Verify data integrity after test migration",
"Execute against production with a transaction wrapper",
"Validate production schema matches expected state",
"Archive the migration with timestamp and hash",
],
best_practices=[
"Always generate rollback scripts BEFORE executing forward migrations",
"Never drop columns in the same migration that adds new ones",
"Use online DDL (pt-online-schema-change) for tables with >1M rows",
"Set a statement timeout to prevent long-running locks",
],
edge_cases=[
"Circular foreign key dependencies require a specific drop order",
"Enum type modifications in PostgreSQL need a CREATE TYPE workaround",
"Partitioned tables may need per-partition migration",
],
allowed_tools=["bash", "read_file", "write_file", "run_sql"],
tags=["database", "migration", "schema", "safety"],
)
Skill Description Optimization
Since skill selection happens entirely through LLM reasoning against the description field, optimizing descriptions is critical:
# BAD: Vague, doesn't help the LLM match queries
bad_description = "Helps with code stuff"
# BAD: Too long, wastes Tier 1 tokens
bad_description_long = """
This skill helps developers write better code by providing comprehensive
code review feedback including style checks, performance analysis,
security vulnerability scanning, test coverage assessment, documentation
review, dependency auditing, and architectural pattern validation across
multiple programming languages including Python, JavaScript, TypeScript,
Go, Rust, Java, and C++.
""" # ~60 tokens — too many for a description
# GOOD: Specific, action-oriented, includes trigger phrases
good_description = """
Performs security-focused code review. Identifies injection vulnerabilities,
auth bypasses, secrets exposure, and insecure deserialization. Use for
PR reviews or codebase security audits.
""" # ~30 tokens — concise, specific, trigger-rich
7. Google ADK’s SkillToolset: Reference Implementation
Google’s Agent Development Kit (ADK) ships with a SkillToolset class that implements the full three-tier disclosure pattern. Here’s how it works conceptually:
from typing import Optional
class SkillToolset:
"""
Simplified reconstruction of Google ADK's SkillToolset.
Provides three tool functions that implement the SKILL.md spec:
- list_skills: Tier 1 (advertise)
- load_skill: Tier 2 (load full body)
- load_skill_resource: Tier 3 (deep dive into references/scripts)
"""
def __init__(self, skills_dir: str):
self.registry = SkillRegistry()
self.registry.discover(project_root=skills_dir)
def list_skills(self) -> list[dict]:
"""
Tool: List all available skills with names and descriptions.
This is what the LLM sees at Tier 1.
"""
return [
{
"name": meta.name,
"description": meta.description,
"allowed_tools": meta.allowed_tools,
}
for meta in self.registry._registry.values()
]
def load_skill(self, skill_name: str) -> dict:
"""
Tool: Load a skill's full instructions (Tier 2).
Returns the SKILL.md body for context injection.
"""
skill = self.registry.activate(skill_name)
return {
"name": skill.metadata.name,
"instructions": skill.body,
"allowed_tools": skill.metadata.allowed_tools,
"available_references": self._list_references(skill),
"available_scripts": self._list_scripts(skill),
}
def load_skill_resource(
self, skill_name: str, resource_path: str
) -> dict:
"""
Tool: Load a specific reference file or execute a script (Tier 3).
For scripts, returns the output — not the source code.
"""
skill = self.registry._loaded.get(skill_name)
if not skill:
return {"error": f"Skill '{skill_name}' not loaded. Call load_skill first."}
resource_file = skill.metadata.path.parent / resource_path
if resource_path.startswith("scripts/"):
executor = SkillExecutor(skill)
output = executor.run_script(resource_file.name)
return {"type": "script_output", "output": output}
else:
content = self.registry.load_reference(skill_name, resource_path)
return {"type": "reference", "content": content}
def _list_references(self, skill: LoadedSkill) -> list[str]:
ref_dir = skill.metadata.path.parent / "references"
if ref_dir.exists():
return [f.name for f in ref_dir.iterdir() if f.is_file()]
return []
def _list_scripts(self, skill: LoadedSkill) -> list[str]:
scripts_dir = skill.metadata.path.parent / "scripts"
if scripts_dir.exists():
return [f.name for f in scripts_dir.iterdir() if f.is_file()]
return []
8. Real-World Patterns and Production Considerations
8.1 Token Budget Management
In production, you need to actively manage the token budget across skills:
class TokenBudgetManager:
"""Enforce token limits across skill loading."""
def __init__(self, max_skill_tokens: int = 20_000):
self.max_tokens = max_skill_tokens
self.current_usage = 0
self._loaded_costs: dict[str, int] = {}
def can_load(self, estimated_tokens: int) -> bool:
return (self.current_usage + estimated_tokens) <= self.max_tokens
def register_load(self, skill_name: str, tokens: int):
self._loaded_costs[skill_name] = tokens
self.current_usage += tokens
def register_unload(self, skill_name: str):
tokens = self._loaded_costs.pop(skill_name, 0)
self.current_usage -= tokens
def get_remaining(self) -> int:
return self.max_tokens - self.current_usage
8.2 Skill Versioning and Cache Invalidation
Skills evolve. You need to detect when a skill has changed and invalidate cached activations:
import json
from pathlib import Path
class SkillCache:
"""Caches parsed skill metadata with content-hash-based invalidation."""
def __init__(self, cache_path: str = ".skill-cache.json"):
self.cache_path = Path(cache_path)
self._cache = self._load_cache()
def _load_cache(self) -> dict:
if self.cache_path.exists():
return json.loads(self.cache_path.read_text())
return {}
def is_stale(self, skill: SkillMetadata) -> bool:
"""Check if the cached version matches the current file hash."""
cached = self._cache.get(skill.name)
if not cached:
return True # Not cached at all
return cached["hash"] != skill.content_hash
def update(self, skill: SkillMetadata):
self._cache[skill.name] = {
"hash": skill.content_hash,
"path": str(skill.path),
"description": skill.description,
}
self.cache_path.write_text(json.dumps(self._cache, indent=2))
8.3 Skill Composition and Chaining
Complex workflows often require multiple skills to execute in sequence. Here’s a pattern for declarative skill pipelines:
from dataclasses import dataclass
@dataclass
class SkillStep:
skill_name: str
task_template: str # Can reference {previous_result}
condition: str = "always" # "always", "on_success", "on_failure"
class SkillPipeline:
"""Declarative skill pipeline with conditional execution."""
def __init__(self, name: str, steps: list[SkillStep]):
self.name = name
self.steps = steps
def to_skill_md(self) -> str:
"""Generate a meta-skill that orchestrates a pipeline."""
workflow = []
for i, step in enumerate(self.steps):
cond = f" (condition: {step.condition})" if step.condition != "always" else ""
workflow.append(f"{i+1}. Activate skill `{step.skill_name}`{cond}")
workflow.append(f" Task: {step.task_template}")
workflow.append(f" After completion, deactivate `{step.skill_name}`")
return f"""---
name: pipeline-{self.name}
description: >
Orchestrates a multi-step pipeline: {' → '.join(s.skill_name for s in self.steps)}.
Use when the task requires sequential execution of multiple specialized skills.
---
# Pipeline: {self.name}
## Steps
{"chr(10)".join(workflow)}
## Execution Rules
- Execute steps sequentially
- Pass results from each step to the next via
- If a step with condition 'on_failure' exists, execute it only when the preceding step fails
- Dehydrate each skill after its step completes
"""
# Define a CI/CD pipeline as composed skills
ci_cd_pipeline = SkillPipeline(
name="ci-cd",
steps=[
SkillStep("code-review-security", "Review changes in the current branch"),
SkillStep("test-runner", "Run full test suite: {previous_result}"),
SkillStep("deploy-pipeline", "Deploy if tests passed: {previous_result}",
condition="on_success"),
SkillStep("incident-report", "Generate failure report: {previous_result}",
condition="on_failure"),
],
)
9. Community Ecosystem and Adoption Metrics
The SKILL.md specification has seen one of the faster adoption curves in the AI tooling ecosystem, likely because its barrier to entry is almost zero — no SDK to install, no runtime dependency, no build step. As of early 2026:
- Public repositories collectively host over a thousand community-authored skills spanning security, DevOps, data engineering, documentation, and more
- Implementations exist in more than 30 agent-oriented products, ranging from CLI tools (Claude Code, Codex CLI, Gemini CLI) to IDE integrations (Copilot, Cursor, JetBrains Junie)
- The
.agents/skills/directory convention has emerged as the cross-platform discovery path — any spec-compliant agent scans it automatically - Google’s Agent Development Kit (ADK) treats skills as a first-class primitive, shipping a
SkillToolsetclass with dedicatedlist_skills,load_skill, andload_skill_resourcetool functions
The underlying reason this “author once, activate anywhere” model works is the format’s deliberate minimalism: Markdown content, YAML metadata, and a filesystem convention — nothing more.
10. Key Takeaways for Agent Developers
-
Don’t confuse skills with tools. Tools grant discrete capabilities (read, write, search). Skills reshape the agent’s reasoning by injecting domain knowledge into context. Treating them interchangeably leads to architectures that are either bloated or brittle.
-
Invest heavily in the description field. Because skill routing relies entirely on the model’s own judgment against frontmatter descriptions, a vague or verbose description is functionally equivalent to a missing skill — the model will never select it.
-
Progressive disclosure is what makes scale possible. The ~50× reduction in startup tokens is not merely a cost savings; it is the architectural property that allows an agent to have hundreds of installed skills without any degradation in response quality or latency.
-
Keep skills and MCP on separate planes. Skills encode procedural knowledge (how to approach a task). MCP provides connectivity (what services to call). When these layers have no shared state, you gain composability — swap either side without touching the other.
-
Dehydrate aggressively in multi-step workflows. The load → execute → unload → repeat cycle ensures that context consumption tracks the current step, not the cumulative workflow. Without dehydration, a five-skill pipeline can exhaust the context window before reaching step three.
-
Respect the 500-line guideline for Tier 2 bodies. Anything longer should be refactored into
references/files that load on-demand at Tier 3, keeping activation costs predictable. -
Design scripts for minimal, structured output. Since only stdout enters the model’s context, a well-designed skill script functions as a compression layer — transforming hundreds of lines of logic into a handful of actionable output lines.
This article expands on concepts introduced in the Strix newsletter post “What are Agent Skills and How Do Agents Use Them?” with original analysis, architecture diagrams, and production-ready code implementations, but you would use this AT YOUR OWN RISK (see DISCLAIMER). All Python examples are the author’s own work, designed to demonstrate the patterns described in the SKILL.md specification.