Executive Summary
The landscape of information technology is undergoing a paradigm shift, moving from manually operated systems to increasingly autonomous operations powered by artificial intelligence. This transition is most pronounced in the domain of AI assistants, which have evolved from simple, stateless chatbots into sophisticated, persistent agents capable of reasoning, planning, and interacting with complex digital environments. This report provides a comprehensive technical analysis of the architectural foundations underpinning these modern AI agents, with a particular focus on their application within a generic, multi-tenant network observability Software-as-a-Service (SaaS) platform.
Our analysis dissects the core components of agentic systems, including the iterative memory loops, advanced planning frameworks that supersede early models like ReAct, and the repository-aware context management seen in development environments such as Cursor. We explore the transition from simple Retrieval-Augmented Generation (RAG) to more advanced GraphRAG architectures, which leverage structured knowledge graphs to enable complex, multi-hop reasoning—a critical capability for diagnosing issues in distributed network infrastructure [18, 19].
The central thesis of this paper is the proposal of a novel architecture for an AI-powered copilot embedded within a network observability platform. This copilot is designed to ingest and correlate a wide array of telemetry data—including logs, metrics, traces, and crucial network-layer information like Border Gateway Protocol (BGP) and Domain Name System (DNS) telemetry. By creating a unified knowledge base that combines a multi-layered memory system with a dynamic service topology graph, the agent can automate complex incident management workflows, from root cause analysis to natural language investigation.
Finally, the report addresses the formidable challenges of deploying such powerful AI systems in an enterprise context. We detail the stringent security, governance, and compliance requirements necessary for a multi-tenant SaaS environment. This includes architectural patterns for achieving robust tenant isolation using technologies like microVMs, principles for creating auditable and privacy-preserving AI systems aligned with frameworks like the NIST AI RMF [2], and the critical role of Human-in-the-Loop (HITL) oversight. Through diagrams, comparative tables, and illustrative code samples, this paper provides a detailed blueprint for building and integrating the next generation of intelligent, autonomous systems for network operations.
Methodology
The findings presented in this report are the result of a comprehensive analysis of peer-reviewed academic papers, pre-print articles from arXiv, technical blogs from leading technology companies, and official documentation for open-source projects and commercial products. The research focused on literature published between 2022 and 2026, capturing the rapid evolution of Large Language Models (LLMs), agentic architectures, and their application in software engineering and IT operations.
The analytical process involved synthesizing information from disparate sources to identify common architectural patterns, emerging best practices, and significant challenges. Conflicts in information were resolved by prioritizing methodologies and results presented in peer-reviewed papers or those substantiated with robust, verifiable data. Claims from vendor-specific marketing materials were cross-referenced with technical documentation and independent analyses. The proposed architecture for a network observability copilot is a synthetic construct, integrating established principles from the reviewed literature into a novel, domain-specific application. This report, compiled on June 7, 2026, is based on publicly available information and does not reflect the proprietary inner workings of any specific commercial product, representing a potential limitation in scope.
The Anatomy of Modern AI Assistants
The concept of the AI assistant has fundamentally evolved from a passive, request-response mechanism into an active, autonomous agent capable of pursuing long-term goals. This transformation is driven by a new class of architectures that endow Large Language Models (LLMs) with memory, planning capabilities, and the ability to interact with external tools and environments. These systems are no longer just language processors; they are digital agents that perceive, reason, and act within a persistent context, marking a significant step towards more general artificial intelligence.
The Agentic Loop: Core Principles of Operation
At the heart of any modern AI agent is an iterative operational cycle, often referred to as the agent loop. This loop extends the basic functionality of an LLM by placing it within a framework of continuous interaction with an environment. The canonical stages of this loop are perceiving the environment, reasoning about the current state and objectives, creating a plan of action, executing that plan through tool use, and observing the outcome, which then feeds back into the next cycle of perception [3, 4]. This process allows the agent to move beyond single-turn interactions and engage in complex, multi-step tasks that require statefulness and adaptation.
Integral to this agent loop is a more formalized memory process, best described as the write–manage–read cycle [4, 5]. This paradigm treats memory not as a passive data store but as an active, managed component of the agent’s cognitive architecture. In the “write” phase, new information from observations, tool results, or internal reflections is captured and structured. The “manage” phase, a critical differentiator of modern agents, involves sophisticated processes like pruning irrelevant data, compressing information, consolidating related memories, and resolving contradictions to maintain the integrity and utility of the memory store [5]. Finally, the “read” phase involves selectively retrieving the most relevant information to inject into the agent’s working context, thereby informing its reasoning and planning for the next action. This continuous loop of writing, curating, and retrieving information is what enables an agent to learn from experience, maintain a persistent “belief state,” and avoid the context limitations of the underlying LLM [4].
Advanced Memory Architectures: The Foundation of Persistence
The evolution from simple chatbots to persistent agents is largely attributable to the development of sophisticated memory systems that mimic aspects of human cognition. Early agents were constrained by the finite context window of the LLM, effectively suffering from a form of digital amnesia between sessions. Modern architectures overcome this limitation by externalizing memory into a multi-layered structure, offloading the cognitive burden from the model’s parameters to dedicated infrastructure. This allows the agent to build a rich history of experiences and knowledge over time.
Research has converged on a taxonomy of memory that categorizes information by its function and temporal scope. Working Memory is the most immediate layer, operating within the agent’s active context window and holding task-specific information for the current operation [4]. Episodic Memory serves as a long-term log of concrete experiences, storing sequences of actions, observations, and outcomes, often timestamped and scored for importance. From these raw episodes, the agent synthesizes Semantic Memory, which contains abstract, de-contextualized knowledge, such as user preferences, general facts, or learned rules. The final layer is Procedural Memory, which stores reusable skills, executable plans, and heuristics for tool use, enabling the agent to perform familiar tasks more efficiently without re-deriving the solution from scratch [4].
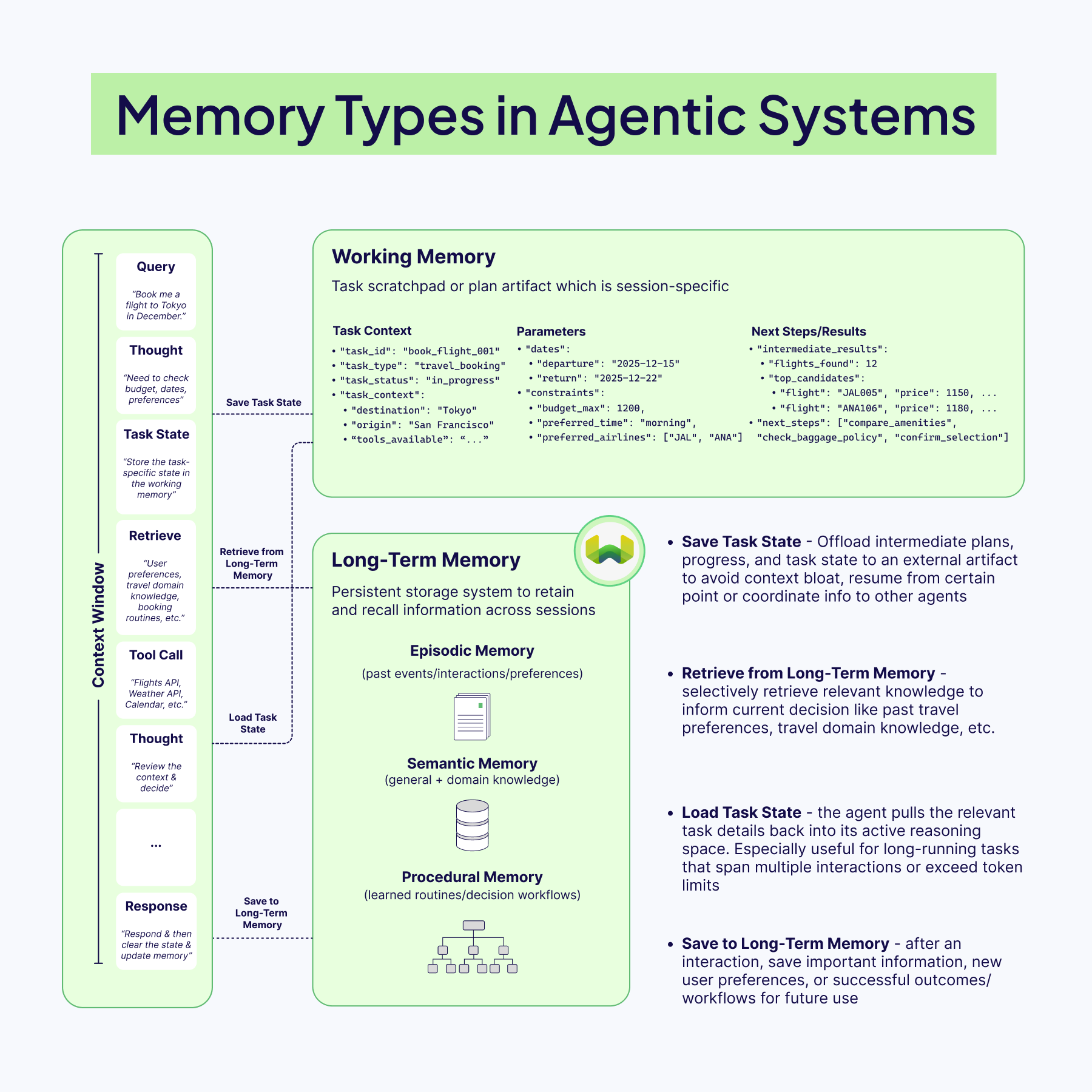 A conceptual model illustrating the distinct layers of memory—Working, Episodic, Semantic, and Procedural—that enable long-term persistence and learning in advanced AI agents.
A conceptual model illustrating the distinct layers of memory—Working, Episodic, Semantic, and Procedural—that enable long-term persistence and learning in advanced AI agents.
Furthermore, state-of-the-art designs are increasingly adopting graph-based memory architectures. Unlike linear logs or unstructured vector databases, knowledge graphs represent information as a network of entities and relationships [6]. This structure preserves causal and hierarchical dependencies, enabling more complex forms of reasoning. For instance, an agent can traverse the graph to perform multi-hop queries, uncovering connections between memories that would be missed by simple semantic similarity search [6]. This capacity for structural reasoning is a crucial enabler for tackling complex, long-horizon problems that require a deep understanding of interconnected concepts.
Planning and Tool Use: From ReAct to Orchestration
An agent’s ability to achieve goals is contingent on its capacity to form coherent plans and execute them by interacting with external tools, such as APIs, databases, or code interpreters. The seminal ReAct (Reason and Act) framework pioneered a powerful paradigm by interleaving reasoning traces (“Thought”) with tool invocations (“Action”) and subsequent “Observations” [7]. This structure forces the LLM to verbalize its reasoning, track its progress, and adjust its plan based on new information. However, the linear, step-by-step nature of ReAct often leads to “local optimization traps,” where the agent gets stuck on a suboptimal path because it lacks a global, high-level strategy [8]. This makes it inefficient for complex tasks that could benefit from parallel execution or a more sophisticated plan.
To overcome these limitations, the field has evolved toward architectures that decouple planning from execution. Planner-centric frameworks employ a dedicated “Planner” agent that first analyzes a complex query and constructs a global execution plan, often represented as a Directed Acyclic Graph (DAG) [8]. This DAG explicitly models dependencies between sub-tasks, allowing an “Executor” or “Worker” agent to run independent tool calls in parallel, significantly reducing latency and improving efficiency.
Another advanced pattern is the use of Multi-Agent Systems, which distribute cognitive labor across a team of specialized agents. In this model, a “Leader” or “Orchestrator” agent is responsible for high-level strategy, task decomposition, and error handling [9]. It delegates specific sub-tasks to a swarm of “Worker” agents, which may be specialized for functions like research, code generation, or data analysis [9, 10]. This hierarchical structure mirrors human engineering teams and reduces the cognitive load on any single model, making it more robust and scalable. These orchestration layers often use deterministic frameworks to manage state and transitions between agents, ensuring that the overall workflow is reliable and auditable [10]. This progression from the simple ReAct loop to complex, orchestrated multi-agent systems represents a significant leap in the ability of AI to perform sophisticated, long-horizon tasks.
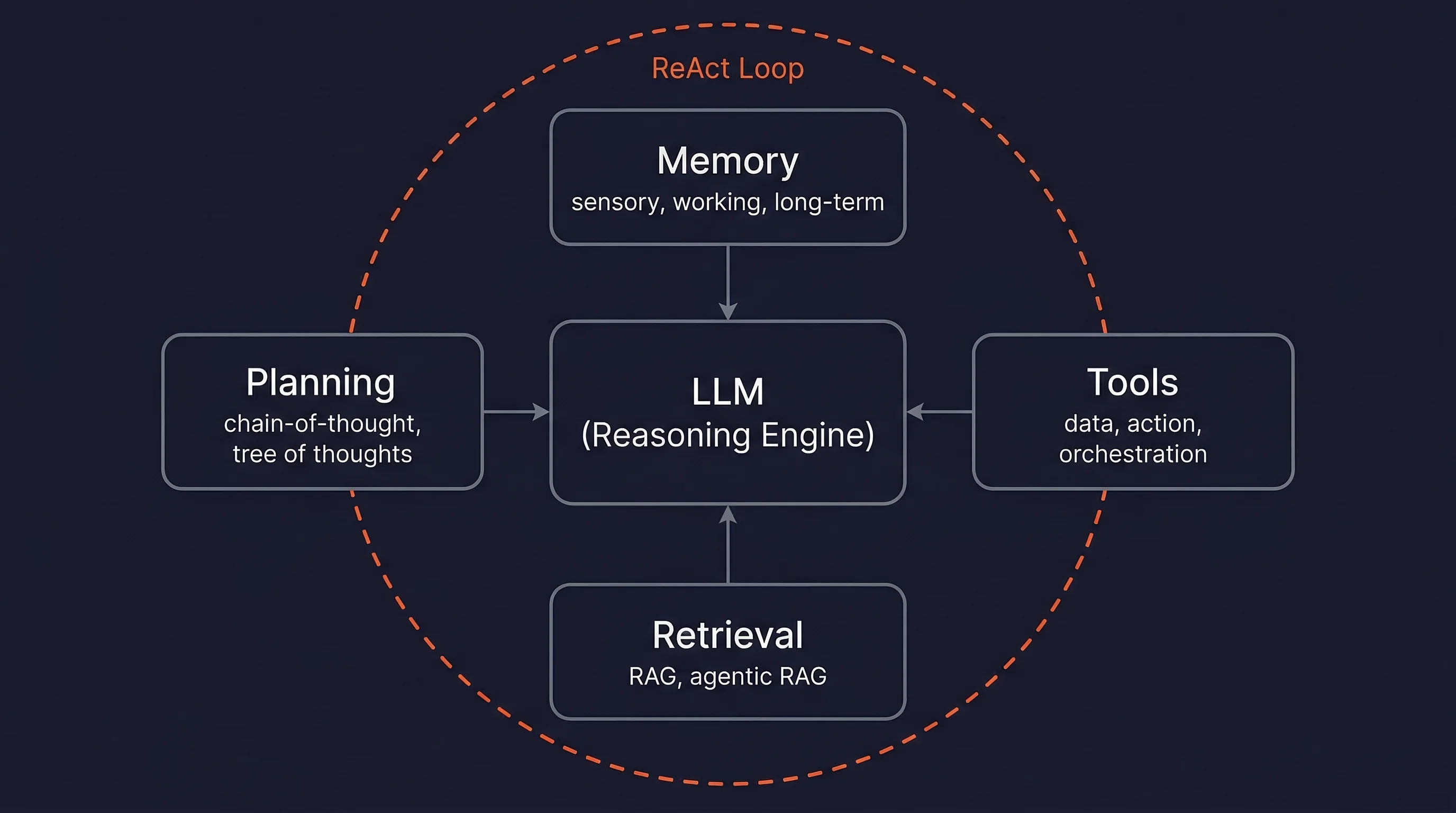 This diagram depicts a modern agentic architecture, highlighting the central role of the agent in coordinating planning, memory retrieval, and tool execution to interact with its environment and achieve goals.
This diagram depicts a modern agentic architecture, highlighting the central role of the agent in coordinating planning, memory retrieval, and tool execution to interact with its environment and achieve goals.
The “Cursor-like” Paradigm: Agentic AI in Development Environments
The integration of agentic AI into software development has given rise to a new generation of tools that transcend simple code completion. The “Cursor-like” paradigm, named after one of its prominent exemplars, represents a developer environment where the AI is not just a passive assistant but an active collaborator with deep awareness of the entire codebase. These systems function as autonomous agents embedded within the Integrated Development Environment (IDE), capable of understanding repository-wide context, orchestrating complex refactoring tasks, and interacting directly with the developer’s command line and file system.
Beyond Autocomplete: Repository-Scale Awareness
Traditional AI coding assistants primarily operated on the local context of the currently open file, offering suggestions based on the surrounding lines of code. This limited their utility for complex tasks that require understanding interdependencies across multiple files, modules, and APIs. Modern agents overcome this by achieving repository-scale awareness. They achieve this by pre-processing the entire codebase to build a persistent, queryable knowledge base [10].
A key technology enabling this is the use of structural parsers like Tree-Sitter to construct knowledge graphs of the code [10]. Instead of treating code as flat text, these agents parse it into a structured representation of entities (e.g., functions, classes, variables) and their relationships (e.g., calls, imports, inheritance). This allows the agent to perform sophisticated structural queries, such as “find all functions that call this deprecated API” or “show me the definition of the class this object inherits from,” without needing to manually read dozens of files. This structural retrieval is far more token-efficient and accurate than naive text-based search [10]. This structured knowledge is often exposed to the agent through a standardized interface known as the Model Context Protocol (MCP), which provides a consistent way for the agent to interact with external knowledge sources and tools, regardless of the underlying infrastructure [11].
A Comparison of Modern AI Coding Assistants
The market for AI coding assistants has matured, with several key players offering distinct approaches to integrating AI into the development workflow. While all aim to boost developer productivity, they differ in their architecture, ecosystem integration, and security postures. The table below compares prominent tools based on available research [12, 13, 14].
| Feature | GitHub Copilot | Cursor | Windsurf |
|---|---|---|---|
| Core Paradigm | Ecosystem-integrated pair programmer | AI-native, repository-aware code editor | Performance-oriented, terminal-aware agent |
| Context Management | Primarily file-level and open tabs, with some repository-level search | Deep codebase indexing via local Merkle trees | “Flow” paradigm with strong terminal and browser context awareness |
| Key Differentiator | Deep integration with GitHub platform (PRs, Actions, Security) | Mature agentic workflows (e.g., “Composer”) and team-wide rule enforcement (.cursorrules) |
High performance and tight integration with the OpenAI ecosystem |
| Security Model | Enterprise-grade compliance, data segregation, and IP indemnification [1] | Local-first indexing; relies on .cursorignore to prevent sensitive data transmission |
Dependent on the underlying OpenAI API security and privacy policies |
| Target User | Developers and teams heavily invested in the GitHub ecosystem | Professional developers and teams seeking a fully AI-integrated editing experience | Developers prioritizing raw performance and a terminal-centric workflow |
This comparison highlights a a fundamental trade-off: deeply integrated ecosystem players like GitHub Copilot provide robust enterprise governance, while more agile, editor-native tools like Cursor offer more advanced agentic workflows at the potential cost of standardized enterprise controls.
Code Sample: A Simplified Agentic Workflow in Python
To make the concept of an agentic workflow more concrete, consider the following pseudo-code example using a hypothetical Python framework. This code illustrates how an agent might perform a simple refactoring task: finding all instances of an old function name and suggesting a replacement. This demonstrates the core loop of planning, acting (tool use), and synthesizing a result.
# A simplified Python pseudo-code example of an agentic workflow for code refactoring.
import agent_framework as af
# Define Tools available to the agent
# In a real system, these would interact with the file system and a structural code index.
class CodebaseTools:
@staticmethod
def find_function_calls(function_name: str) -> list[dict]:
"""Finds all files and line numbers where a function is called."""
print(f"TOOL: Searching for calls to '{function_name}'...")
# In a real implementation, this would query a Tree-Sitter-based index.
return [
{"file": "src/main.py", "line": 56},
{"file": "src/utils.py", "line": 102},
]
@staticmethod
def read_file_line(file_path: str, line_number: int) -> str:
"""Reads a specific line from a file."""
print(f"TOOL: Reading line {line_number} from '{file_path}'...")
# Dummy implementation
if file_path == "src/main.py":
return "result = old_deprecated_function(data)"
return "value = old_deprecated_function(config)"
@staticmethod
def suggest_refactor(file_path: str, line_number: int, old_code: str, new_function_name: str) -> str:
"""Generates a refactoring suggestion for a line of code."""
print(f"TOOL: Generating refactor suggestion for '{file_path}:{line_number}'...")
# This function would use an LLM to generate the replacement code.
new_code = old_code.replace("old_deprecated_function", new_function_name)
return f"Replace line {line_number} in '{file_path}' with: `{new_code}`"
# Create an agent with a set of tools
agent = af.Agent(
name="RefactoringAgent",
tools=[
CodebaseTools.find_function_calls,
CodebaseTools.read_file_line,
CodebaseTools.suggest_refactor,
],
model="gpt-4-turbo" # Specify the LLM to use for reasoning
)
# The User's request
user_request = "Please find all uses of 'old_deprecated_function' and replace them with 'new_stable_function'."
# Agent execution loop
def run_refactoring_agent(request: str):
"""Orchestrates the agent's plan to fulfill the user request."""
print("AGENT: Received request. Devising a plan.")
# 1. Plan: The agent's LLM brain decides the sequence of actions.
plan = [
"Use the 'find_function_calls' tool to locate all instances of 'old_deprecated_function'.",
"For each instance found, use the 'read_file_line' tool to get the exact code.",
"Use the 'suggest_refactor' tool to generate a replacement for each line.",
"Compile all suggestions into a final report for the user."
]
print("AGENT: Plan created:\n" + "\n".join(f"- {step}" for step in plan))
# 2. Act: The agent executes the plan by calling the tools.
old_function = "old_deprecated_function"
new_function = "new_stable_function"
call_locations = agent.run_tool("find_function_calls", function_name=old_function)
suggestions = []
for loc in call_locations:
line_content = agent.run_tool("read_file_line", file_path=loc["file"], line_number=loc["line"])
suggestion = agent.run_tool("suggest_refactor", file_path=loc["file"], line_number=loc["line"], old_code=line_content, new_function_name=new_function)
suggestions.append(suggestion)
# 3. Observe/Synthesize: The agent compiles the results into a human-readable format.
final_report = "Refactoring complete. Here are the suggested changes:\n\n" + "\n".join(suggestions)
print("\nAGENT: Final Report:\n" + final_report)
# Run the agent
run_refactoring_agent(user_request)
This example, while simplified, captures the essence of the “Cursor-like” paradigm: an agent that can reason about a user’s intent, formulate a multi-step plan, interact with the codebase through specialized tools, and synthesize the results into a concrete, actionable outcome.
Architecting an AI Assistant for Network Observability SaaS
The explosive growth in the complexity of distributed systems has turned network and service monitoring into a significant challenge for IT operations and Site Reliability Engineering (SRE) teams. These teams are inundated with a constant stream of telemetry data from countless sources—logs, metrics, traces, and network protocol updates. An AI assistant, or copilot, embedded within a network observability SaaS platform presents a powerful opportunity to automate the cognitive-heavy tasks of incident investigation, root cause analysis, and proactive system management, transforming a reactive operational model into a proactive, data-driven one.
The Opportunity: Taming Complexity in Network Monitoring
The core problem in modern network observability is not a lack of data, but a surplus of it [15]. Human operators struggle to manually correlate disparate signals to diagnose issues. For example, a latency spike observed in application metrics might be caused by a database overload, a misconfigured load balancer, an upstream API failure, or a sub-optimal BGP routing change happening thousands of miles away [16, 17]. Pinpointing the true root cause requires expertise, time, and the painstaking process of cross-referencing data from multiple, often siloed, monitoring tools.
An agentic AI assistant is uniquely suited to address this challenge. By leveraging its ability to ingest and reason over vast, heterogeneous datasets, it can automate the correlation process that is so burdensome for humans [21]. It can answer natural language questions about system health, automatically investigate alerts as they fire, and provide evidence-backed explanations for its conclusions. This allows human experts to focus their attention on strategic remediation and system improvement rather than getting lost in the weeds of diagnostic data analysis.
A Proposed Architecture for a Network Observability Copilot
To realize this vision, we propose a multi-component architecture for a network observability copilot that integrates the advanced agentic principles discussed previously. This architecture is centered around a sophisticated knowledge base that combines a multi-layered memory system with a dynamic knowledge graph, serving as the AI’s long-term memory and world model.
 An example of a GraphRAG architecture, which combines semantic search with graph traversal to retrieve interconnected, contextual information for the LLM, a model well-suited for a network observability copilot.
An example of a GraphRAG architecture, which combines semantic search with graph traversal to retrieve interconnected, contextual information for the LLM, a model well-suited for a network observability copilot.
The ingestion layer of this architecture would continuously process telemetry streams from various sources. Application logs, system metrics, and distributed traces provide a view of the service layer, while specialized data feeds for BGP updates, DNS query responses, and flow records (like IPFIX) offer crucial visibility into the underlying network fabric [16]. This data is then processed and stored within the agent’s memory system.
- Episodic Memory: This layer would store a historical record of all incidents, including the alerts that triggered them, the investigation steps taken (both by humans and the AI), chat transcripts from incident response channels, and the final resolution. Each incident becomes a discrete “episode” that the agent can learn from [4].
- Semantic Memory: Through a process of periodic reflection and summarization, the agent distills higher-level knowledge from raw episodes. This semantic store might contain insights like, “Deployments to the ‘us-east-1’ region containing database schema changes have a 30% higher chance of causing P1 incidents,” or summaries of service runbooks [4].
- Procedural Memory: This layer stores learned, executable workflows for diagnosing specific types of alerts. For example, upon receiving a “high latency” alert for a particular service, the agent could invoke a pre-defined procedure that automatically checks database load, recent deployments, and upstream service health in a specific sequence [4].
- Graph-Based Knowledge Base: This is the centerpiece of the architecture. It is a dynamic knowledge graph that models the entire monitored environment as a set of interconnected entities. Nodes in the graph would represent services, databases, Kubernetes pods, hosts, and network prefixes. Edges would represent dependencies, communication pathways, and logical relationships (e.g., “Service A depends on Database B,” “Pod X runs on Host Y,” “Traffic to Prefix Z traverses AS Path [1]”). This GraphRAG (Graph Retrieval-Augmented Generation) approach allows the agent to reason about the system’s topology and perform multi-hop queries to understand the “blast radius” of a failure [18, 19].
Agentic Workflows for Incident Management
With this architecture in place, the observability copilot can execute a range of sophisticated workflows that automate and augment the incident management lifecycle. A multi-agent system, comprising a high-level Orchestrator and specialized Worker agents, would be ideal for managing these complex tasks [9].
-
Use Case 1: Automated Root Cause Analysis (RCA): When a critical alert fires, the Orchestrator agent initiates an investigation. It spawns multiple Worker agents in parallel. One agent analyzes metric data to characterize the anomaly’s scope and timing. Another agent scans log files from the affected service for error messages within the same timeframe. A third, specialized “Network Agent,” queries the knowledge graph to check for any correlating BGP path changes or DNS anomalies that occurred concurrently [20, 22]. The agents feed their findings back to the Orchestrator, which uses the LLM’s reasoning capabilities to synthesize the information, identify the most probable root cause, and present a cited, evidence-backed summary to the on-call engineer.
-
Use Case 2: Natural Language Investigation: An SRE can interact with the copilot in a conversational manner. For example, they might ask, “What was the impact of the BGP route leak this morning affecting our primary European prefixes?” The Orchestrator agent would parse this query, identify the key entities (“BGP route leak,” “European prefixes”), and delegate the investigation. A Worker agent would query the Episodic memory for the relevant incident record from that morning. Another agent would query the knowledge graph to identify all services dependent on infrastructure associated with those prefixes [20]. The final response would be a comprehensive summary, including which services experienced increased latency, the duration of the impact, and a link to the full post-mortem report.
-
Use Case 3: Proactive Anomaly Explanation: The copilot can also operate proactively. A monitoring agent could continuously analyze network telemetry for subtle performance degradations that might not trigger a hard alert threshold. Upon detecting a consistent increase in latency for traffic routed through a specific Internet Service Provider (ISP), the agent could proactively generate a report explaining the anomaly, identifying the affected customer traffic, and suggesting potential traffic engineering adjustments to mitigate the issue before it becomes a major incident [22].
Illustrative Code Sample: Diagnosing a Network Anomaly
The following Python pseudo-code provides a conceptual look at how an agent function might approach diagnosing a latency spike. It demonstrates the correlation of multiple data sources, a key capability of the proposed architecture.
# A simplified Python pseudo-code example for a network observability agent function.
from observability_tools import MetricsDB, TracesDB, BGPLogDB, ServiceGraph
class ObservabilityAgent:
def __init__(self):
# Initialize connections to data sources and the knowledge graph
self.metrics = MetricsDB()
self.traces = TracesDB()
self.bgp_logs = BGPLogDB()
self.service_graph = ServiceGraph()
self.llm = "anthropic.claude-3-opus-20240229-v1:0" # The reasoning engine
def diagnose_latency_spike(self, alert_details: dict) -> str:
"""
Investigates a latency spike alert by correlating metrics, traces, and network data.
"""
service_name = alert_details["service"]
start_time = alert_details["start_time"]
end_time = alert_details["end_time"]
# --- Step 1: Gather Initial Evidence from different telemetry sources ---
# Agent analyzes metrics to confirm the spike
metric_summary = self.metrics.get_latency_summary(service_name, start_time, end_time)
# Agent finds the slowest traces during the incident window
slowest_traces = self.traces.find_slowest_traces(service_name, start_time, end_time)
# Agent checks for any BGP routing changes in the same window
bgp_changes = self.bgp_logs.get_updates_for_prefixes(
service_prefixes=self.service_graph.get_prefixes_for_service(service_name),
start_time=start_time,
end_time=end_time
)
# --- Step 2: Formulate Hypotheses based on Evidence ---
causal_hypotheses = []
if "database_query" in str(slowest_traces):
causal_hypotheses.append("The latency spike may be caused by slow database queries.")
downstream_services = self.service_graph.get_downstream_dependencies(service_name)
if any(service in str(slowest_traces) for service in downstream_services):
causal_hypotheses.append("The issue may originate from a slow downstream dependency.")
if bgp_changes:
causal_hypotheses.append(f"A concurrent BGP routing change was detected, potentially causing suboptimal traffic paths. Changes: {bgp_changes}")
# --- Step 3: Synthesize a Root Cause Narrative using the LLM ---
prompt = f"""
You are an expert SRE. A latency spike was detected for the service '{service_name}'.
Analyze the following evidence and provide a concise root cause analysis.
Metric Summary: {metric_summary}
Slowest Traces Analysis: The slowest traces show significant time spent in these spans: {slowest_traces}.
BGP Log Analysis: The following BGP updates were observed during the incident: {bgp_changes}.
Causal Hypotheses: {causal_hypotheses}
Based on all evidence, what is the most likely root cause? Be precise and provide your reasoning.
"""
# The LLM reasons over the correlated data to generate an explanation.
root_cause_narrative = self.llm.generate(prompt)
return root_cause_narrative
# --- Example Usage ---
# An alert comes in from the monitoring system.
alert = {
"service": "api-gateway",
"alert_type": "P95_LATENCY_SPIKE",
"start_time": "2026-06-07T10:00:00Z",
"end_time": "2026-06-07T10:15:00Z"
}
# The agent is triggered to perform RCA.
agent = ObservabilityAgent()
analysis_report = agent.diagnose_latency_spike(alert)
print("--- Automated Incident Analysis Report ---")
print(analysis_report)
This example illustrates how an agent can systematically gather and correlate evidence from multiple domains—application performance and network routing—to form and evaluate hypotheses, ultimately producing a coherent and actionable analysis that would be time-consuming and difficult for a human operator to construct under pressure.
Enterprise Integration: Security, Governance, and Compliance
Integrating a powerful, autonomous AI copilot into an enterprise-grade, multi-tenant SaaS platform is not merely a technical challenge; it is a profound security and governance undertaking. The very capabilities that make these agents effective—access to vast data stores, the ability to interact with production systems, and autonomous decision-making—also introduce significant risks if not architected with a security-first mindset. For a network observability product serving multiple customers, ensuring absolute tenant isolation, data privacy, and regulatory compliance is paramount.
The Multi-Tenant Security Challenge
In a multi-tenant environment, the primary threat is data leakage across tenant boundaries. An AI assistant, by its nature, processes large amounts of contextual data. A single flaw in its logic or a vulnerability to a technique like prompt injection could lead to catastrophic consequences [23, 24]. A malicious actor in one tenant could craft a query designed to trick the agent into revealing sensitive data—such as infrastructure details, proprietary code, or PII—from another tenant. Furthermore, the risk of “excessive agency,” where an agent is manipulated into performing unauthorized actions, is a critical concern identified by security frameworks like the OWASP Top 10 for LLM Applications [23]. The non-deterministic nature of LLMs means that traditional application security models, which rely on predictable code paths, are insufficient. Security cannot be an afterthought; it must be structurally embedded in the architecture.
Architectural Patterns for Secure Multi-Tenancy
To mitigate these risks, a defense-in-depth strategy based on structural isolation is required [26]. This principle dictates that tenant separation should be enforced by the underlying infrastructure, not by application-level logic that could be flawed or bypassed. Several architectural patterns are key to achieving this.
-
Compute and Runtime Isolation: AI agents that execute LLM-generated or un-trusted code pose a significant threat. Standard containerization, which shares the host kernel, is often insufficient. A stronger approach is to use lightweight virtual machines, or microVMs, such as those created by Firecracker [25]. Firecracker provides hardware-level virtualization, ensuring that each tenant’s agent execution (or even each individual agent invocation) occurs in a completely separate kernel environment [25, 26]. This prevents container escape vulnerabilities and ensures that one tenant’s processes cannot interfere with another’s.
-
Data and Credential Security: The agent’s access to data must be rigorously controlled. Instead of relying on application logic like
WHERE tenant_id = X, a more robust pattern is namespace separation, where each tenant’s data resides in a physically separate storage bucket, database schema, or vector collection [27]. This makes cross-tenant access impossible by design. Furthermore, a tenant-aware proxy should be placed between the agent and any backend services. This proxy is responsible for stripping any credentials the agent might erroneously inject into a request and unconditionally rewriting tenant identifiers based on the trusted session context, preventing the model from hallucinating or being tricked into accessing another tenant’s resources [28].
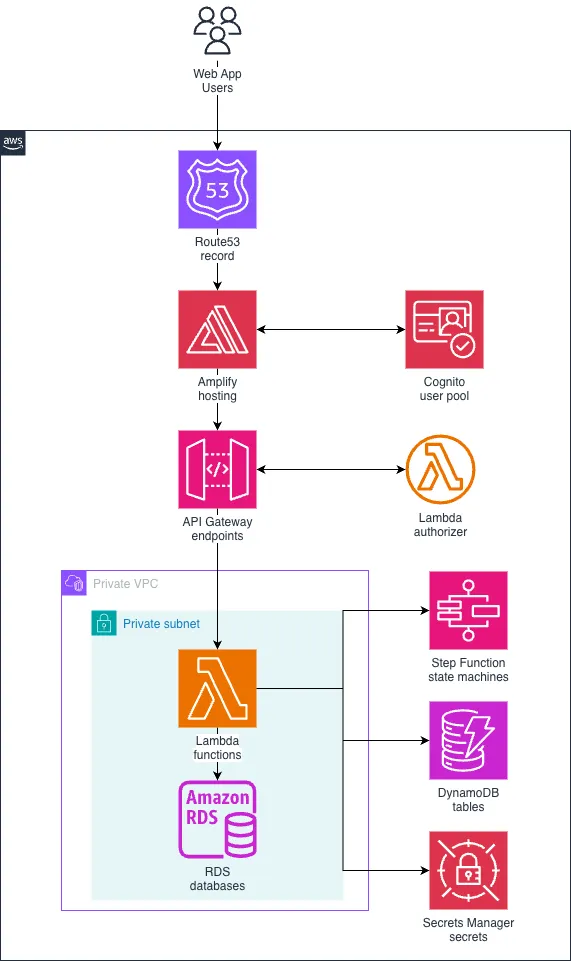 This architectural diagram illustrates a multi-tenant AI platform, emphasizing data segregation and isolated processing, which are critical for enterprise security.
This architectural diagram illustrates a multi-tenant AI platform, emphasizing data segregation and isolated processing, which are critical for enterprise security.
Governance, Auditability, and Human-in-the-Loop (HITL)
Beyond infrastructure security, robust governance and oversight mechanisms are essential for building trust and meeting regulatory requirements. Organizations should align their AI governance strategy with established frameworks like the NIST AI Risk Management Framework (AI RMF), which provides a structured approach to identifying, measuring, and managing AI-related risks [2].
Role-Based Access Control (RBAC) must be extended to the AI agents themselves. Each agent should be treated as a non-human identity with its own set of permissions, adhering to the principle of least privilege [31]. This ensures that an agent authorized to read observability data cannot, for instance, execute a command to modify a network device configuration unless explicitly permitted for that user’s role.
A comprehensive AI Audit Trail is non-negotiable. Traditional logging is insufficient because it only captures the state of the system. An AI audit trail must log the intent and reasoning of the agent [29]. This includes logging the full prompt, the retrieved context, the “thought” process or plan generated by the LLM, the specific tools called, and the final output [30]. This level of traceability is crucial for forensic analysis, debugging, and demonstrating compliance to regulators.
Finally, for high-stakes actions, a Human-in-the-Loop (HITL) workflow is essential. While the AI agent can autonomously perform analysis and suggest remediation steps (e.g., “roll back deployment X” or “apply this traffic filter”), the final execution of any action that modifies the production environment must require explicit approval from a human operator [32]. The system must balance the need for safety with the operational desire for low latency by using smart escalation policies, routing only the most critical or ambiguous decisions for human review [33].
Comparison of Security Isolation Models
The choice of an isolation model involves a trade-off between security, cost, and complexity. The following table compares different approaches an organization might consider when architecting a multi-tenant AI SaaS product.
| Isolation Model | Isolation Strength | Typical Cost | Implementation Complexity | Performance Overhead |
|---|---|---|---|---|
| Logical (Row-Level Security) | Weakest | Low | Low | Minimal |
| Application-Level Namespacing | Moderate | Low | Moderate | Low |
| Container-Based Isolation | Strong | Moderate | Moderate | Moderate |
| MicroVM-Based Isolation | Strongest | High | High | High |
| Physical (Dedicated Hardware) | Absolute | Very High | Very High | None (per tenant) |
For a network observability SaaS product handling sensitive customer data, a model combining application-level namespacing for data storage with microVM-based isolation for compute workloads offers a strong balance of security and scalability [26]. While more complex to implement than simpler models, this hybrid approach provides the necessary defense-in-depth to earn the trust of enterprise customers.
Conclusion
The evolution of AI assistants into persistent, autonomous agents marks a pivotal moment for enterprise software, particularly in complex domains like network observability. The architectural patterns that have emerged—sophisticated multi-layered memory, advanced planning and orchestration frameworks, and repository-aware context management—provide the foundational components for building truly intelligent systems. These agents are no longer just tools but are becoming active collaborators, capable of automating the cognitively demanding work of incident investigation and root cause analysis.
This report has proposed a comprehensive architecture for a network observability copilot, one that leverages these principles to tame the overwhelming firehose of modern telemetry data. By integrating a GraphRAG knowledge base that unifies service topology with network path information, such a system can perform complex, multi-hop reasoning, correlating signals across application and network layers to provide rapid, evidence-backed insights. The potential to drastically reduce mean time to resolution, eliminate dependency on tribal knowledge, and shift human operators from reactive firefighting to proactive optimization is immense.
However, this great power comes with great responsibility. The successful deployment of agentic AI in a multi-tenant SaaS environment is contingent upon a security-first approach. Robust structural isolation, fine-grained access control, comprehensive auditability of agent reasoning, and unwavering human oversight for critical actions are not optional features but core design requirements. As we move forward, the organizations that succeed will be those that master this duality—innovating boldly with agentic AI while grounding their systems in the unshakeable principles of security, governance, and trust.
References
- Enforcing policies for GitHub Copilot in your enterprise - GitHub Docs
- NIST AI Risk Management Framework (AI RMF 1.0), Generative Artificial Intelligence Profile (NIST AI 600-1), July 2024
- “What is the AI Agent Loop?”, Oracle Developer Resource Center
- A Survey on Large Language Model-based Autonomous Agents, March 2024
- A Practical Guide to Memory for Autonomous LLM Agents, Towards Data Science
- From Language Models to Practical Agents: A Survey on Memory Mechanisms, February 2024
- ReAct: Synergizing Reasoning and Acting in Language Models, October 2022
- Beyond ReAct: A Plan-centric Approach for Action-Generation Models, November 2023
- “Hierarchical LLM-agent for solving complex enterprise-scenario tool-use tasks”, December 2023
- “Agentic Engineering: Redefining Software Engineering with AI”, LangChain Blog
- Codebase-Memory: A Code Language Model with Repository-Scale Read and Write Operations, March 2024
- “GitHub Copilot vs Cursor”, Wiz Academy
- “Cursor: The AI-first Code Editor”, The Pragmatic Engineer
- “GitHub Copilot vs Cursor vs Windsurf”, Digital Applied
- “Correlating Metrics, Traces, and Logs for Holistic Visibility”, Site24x7
- “BGP in Flow Analysis (IPFIX/NetFlow)”, Kentik
- “Mastering Network Path Observability”, Catchpoint
- From Local to Global: A Graph-Based Approach for Multi-Document RAG, February 2024
- GraphRAG: A Cost-Effective Framework for Enterprise-Level Retrieval-Augmented Generation, July 2024
- “AI Root Cause Analysis”, Coroot
- “What is AI SRE? The Ultimate Guide for 2026”, incident.io
- BEAR: A Framework for BGP Event Analysis and Reporting with Large Language Models (LLMs), June 2024
- OWASP Top 10 for Large Language Model Applications
- The Security of LLM-based Applications in a Multi-tenant Environment, April 2024
- Firecracker MicroVM
- “SaaS Isolation for AI Agents: A Deep Dive into Multi-Tenant Security”, Blaxel
- “Isolation Boundaries: A Guide to Multi-Tenant AI Architecture Guardrails”, DZone
- “Defense in Depth: Tenant Isolation for an Agent That Executes Code”, Dev.to
- “Auditing and Logging AI Agent Activity: A Developer’s Guide”, LoginRadius Engineering Blog
- “AI Audit Trail: Navigating Regulatory Scrutiny”, CXtoday
- “Architecting Trust: A NIST-based Security Governance Framework for AI Agents”, Microsoft Defender for Cloud Blog
- “Human in the Loop for Agentic AI”, Elementum
- The Human-in-the-Loop Framework at Comet
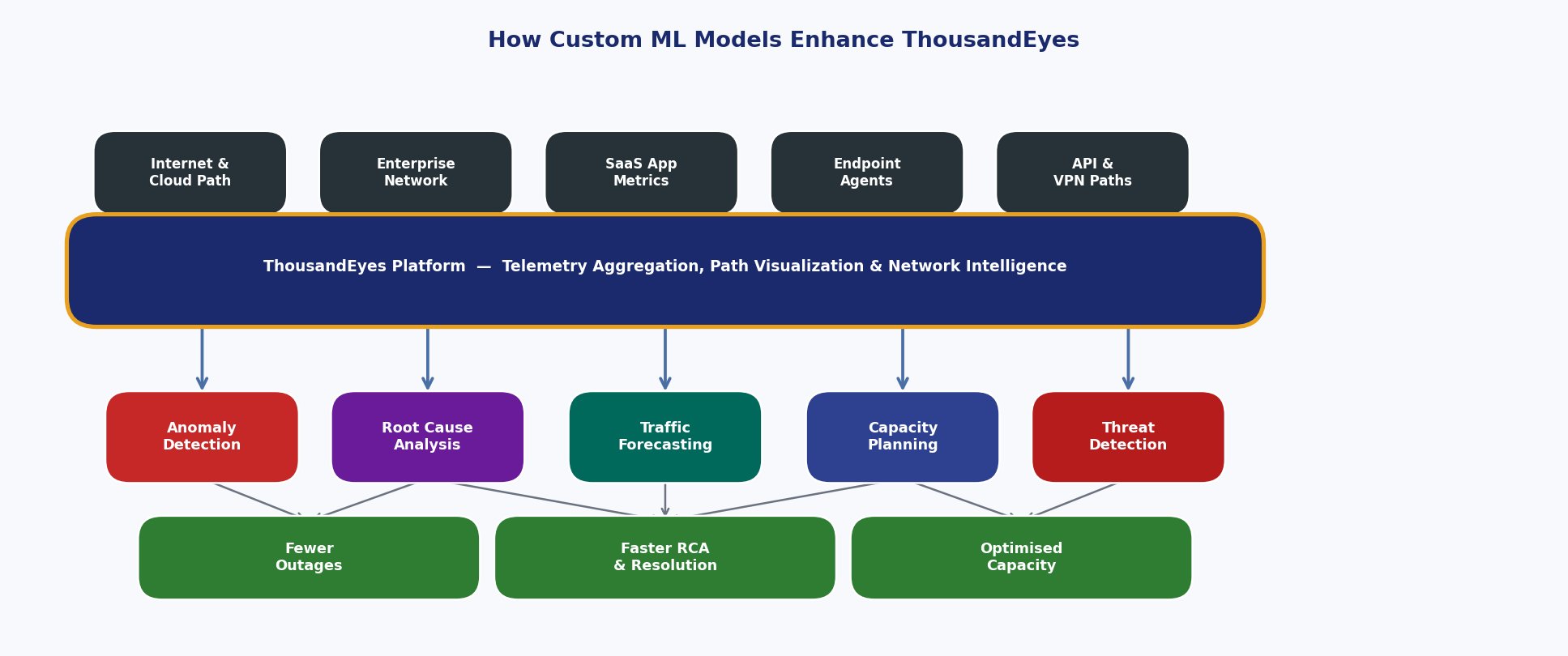
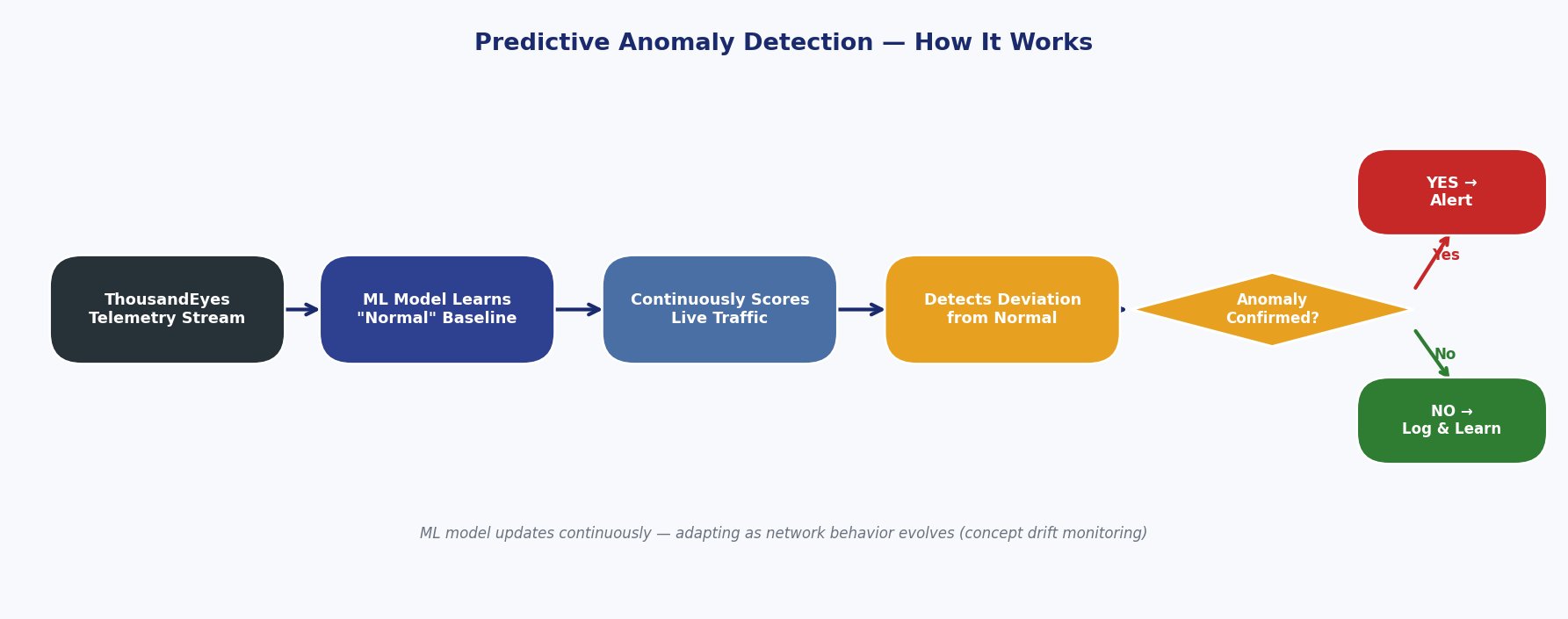
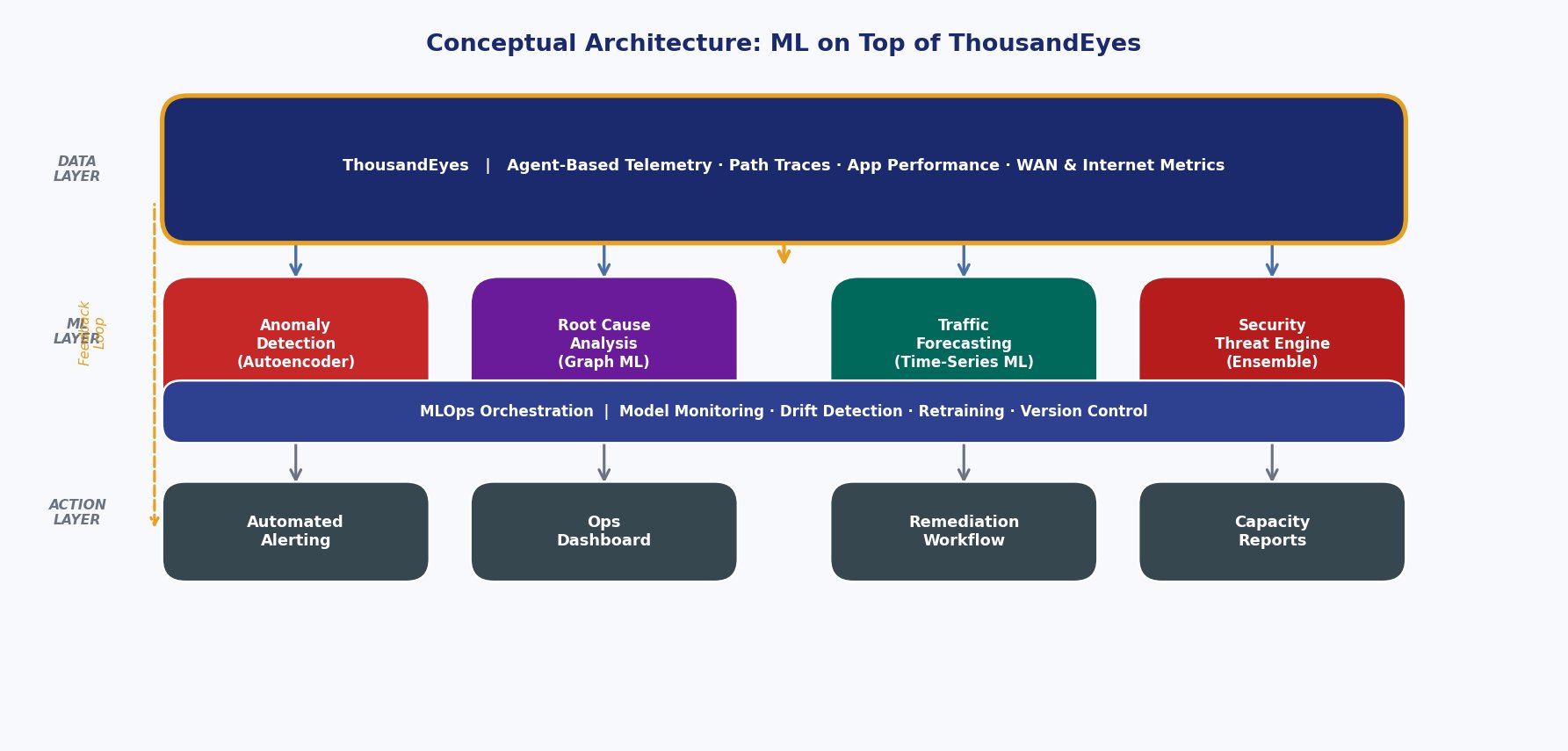
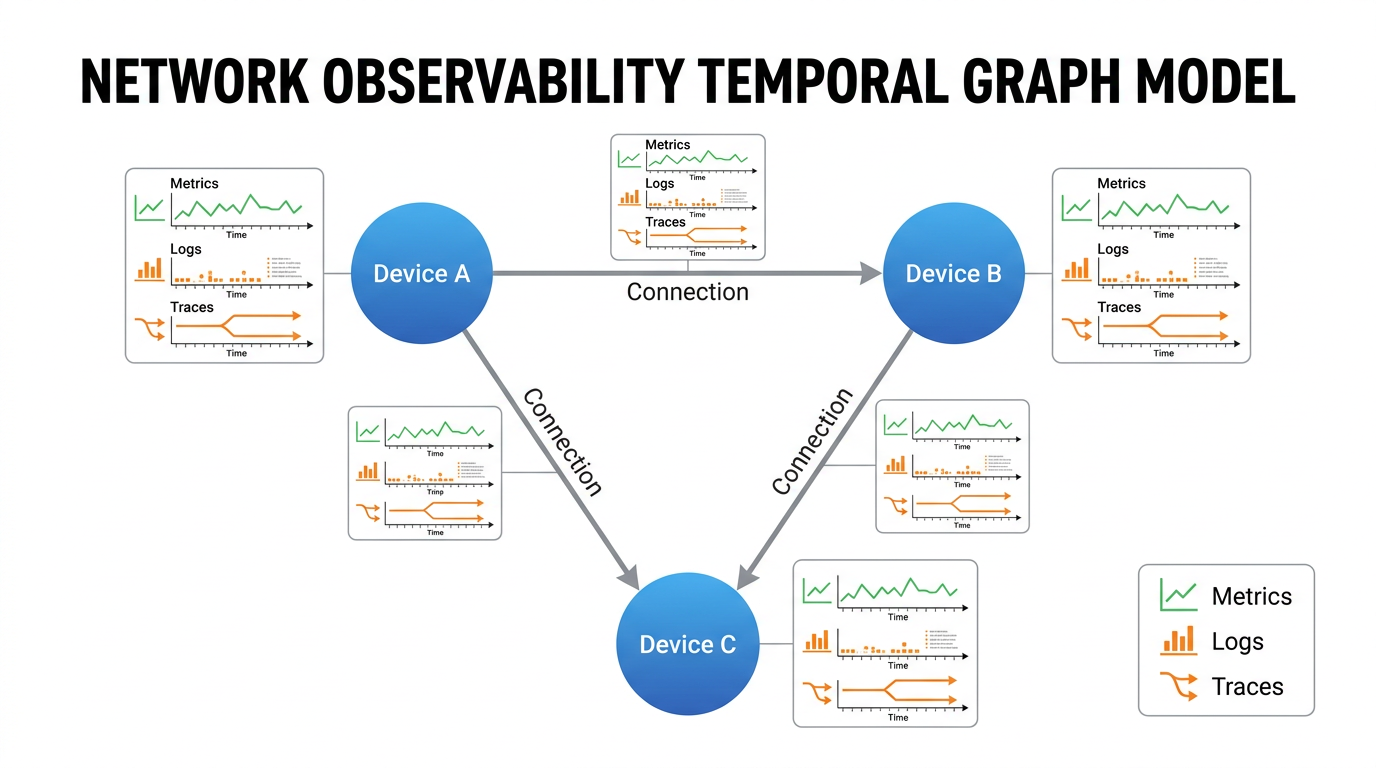 Figure 1: Conceptual mapping of network state over time to a sequence of graph snapshots, forming the basis for spatiotemporal analysis.
Figure 1: Conceptual mapping of network state over time to a sequence of graph snapshots, forming the basis for spatiotemporal analysis.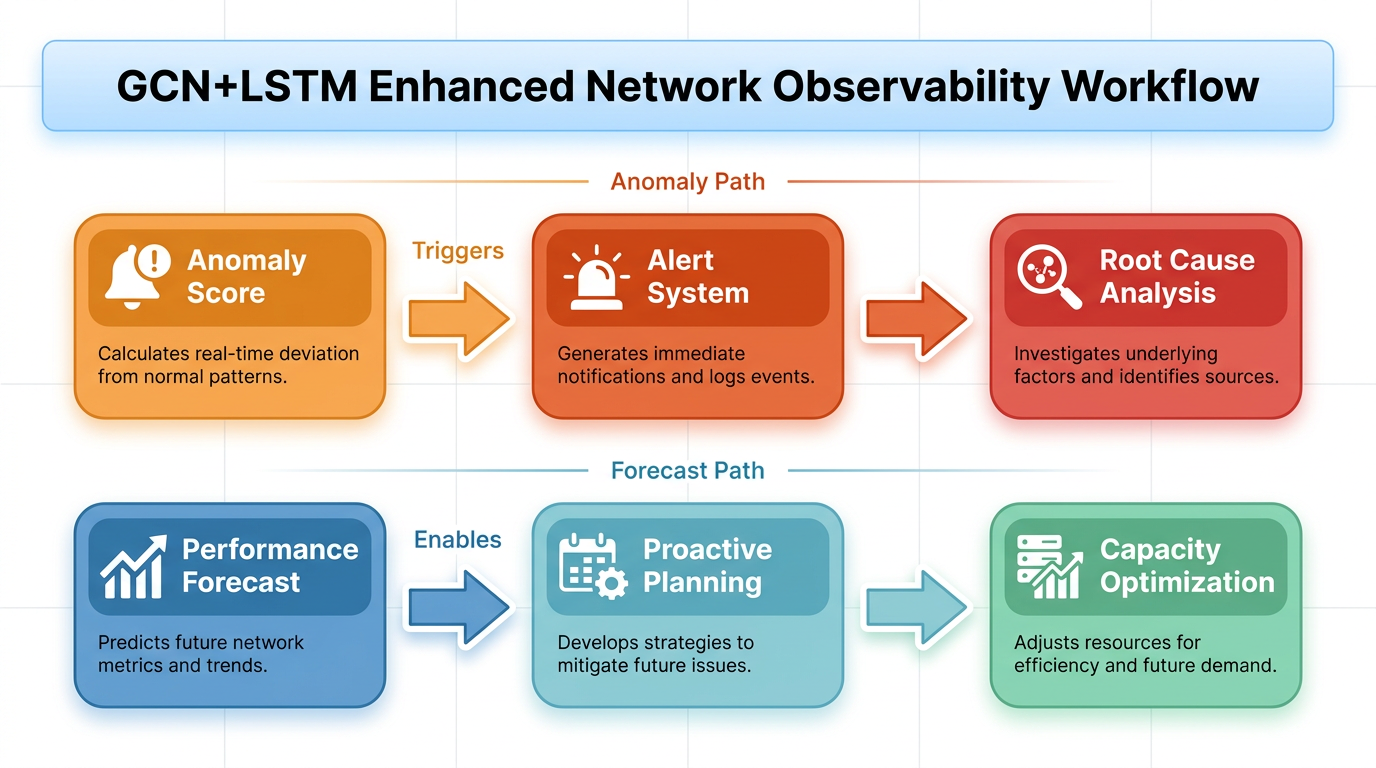 Figure 2: The role of GCN+LSTM model outputs in an integrated observability workflow, enabling proactive and automated operational responses.
Figure 2: The role of GCN+LSTM model outputs in an integrated observability workflow, enabling proactive and automated operational responses.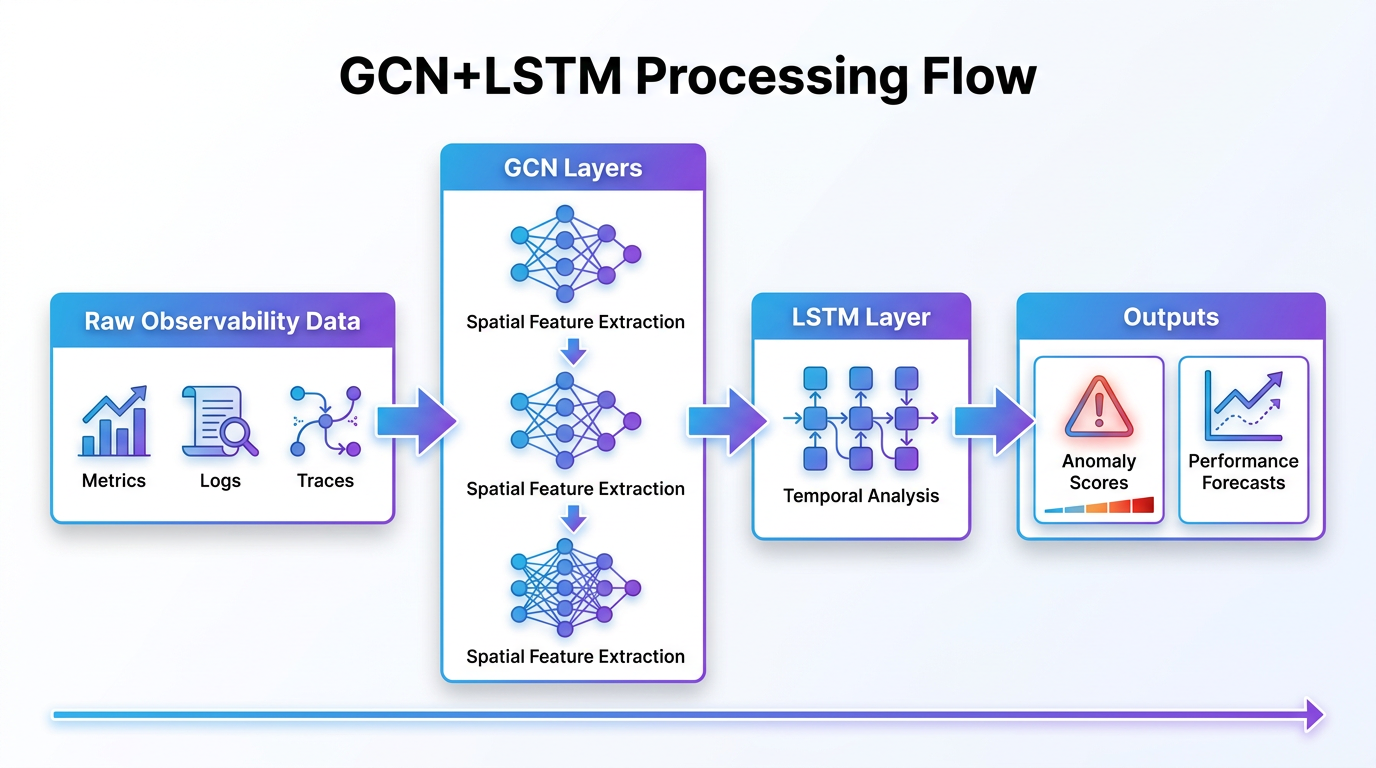 Figure 3: Architectural overview of the GCN+LSTM processing pipeline, showing the flow from graph sequences to spatiotemporal encoding and final prediction.
Figure 3: Architectural overview of the GCN+LSTM processing pipeline, showing the flow from graph sequences to spatiotemporal encoding and final prediction.

 Actual digit images from the dataset. Each is a tiny 32x32 pixel grayscale crop from a street-level photo. Notice the noise, blur, and varying lighting – this is not a clean laboratory dataset.
Actual digit images from the dataset. Each is a tiny 32x32 pixel grayscale crop from a street-level photo. Notice the noise, blur, and varying lighting – this is not a clean laboratory dataset.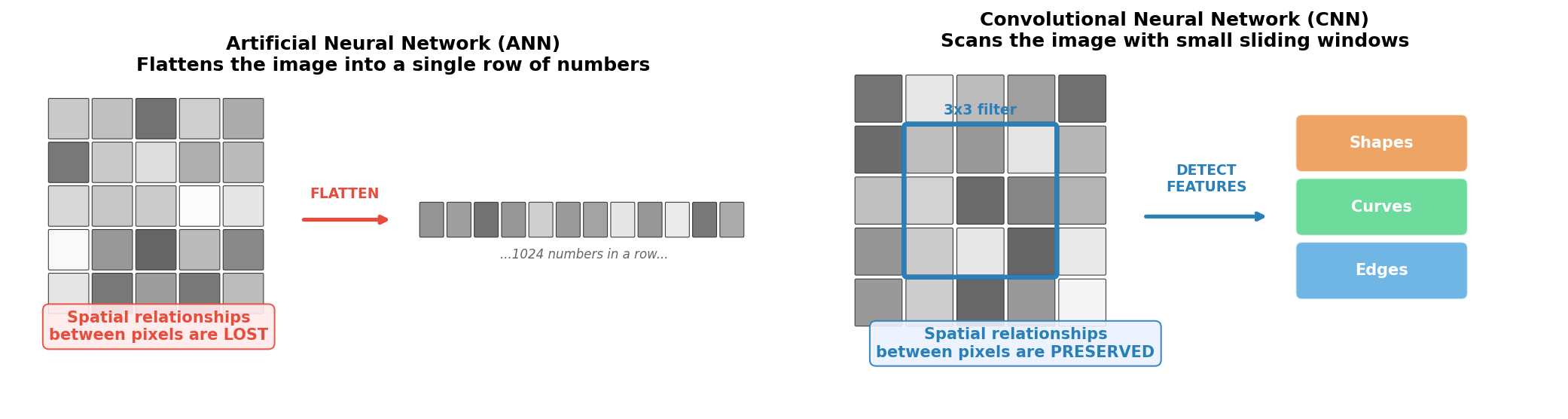 The fundamental difference. An ANN flattens the image into a long list of numbers, destroying the spatial layout. A CNN keeps the 2D structure intact and scans for visual features like edges and curves – the way a human eye would.
The fundamental difference. An ANN flattens the image into a long list of numbers, destroying the spatial layout. A CNN keeps the 2D structure intact and scans for visual features like edges and curves – the way a human eye would.
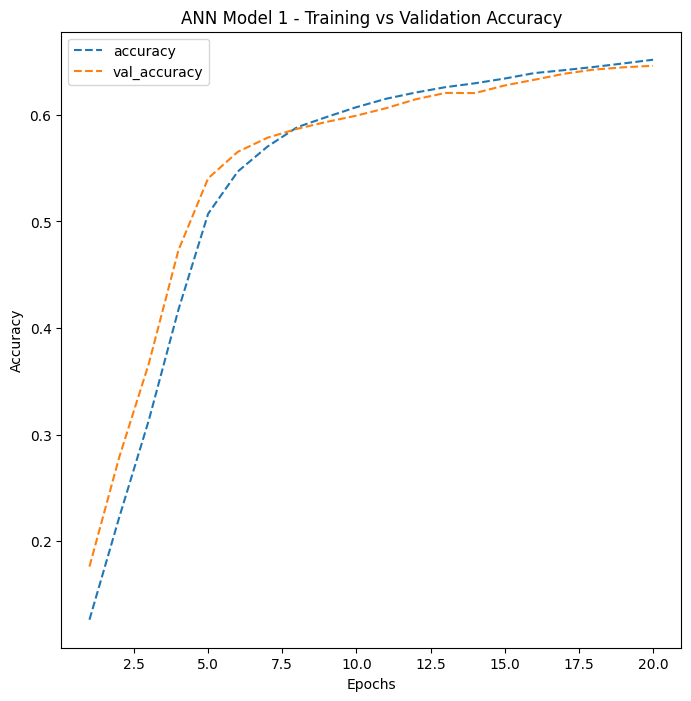 ANN Model 1’s training curve. Both training and validation accuracy plateau quickly, indicating the model has reached its capacity limit.
ANN Model 1’s training curve. Both training and validation accuracy plateau quickly, indicating the model has reached its capacity limit.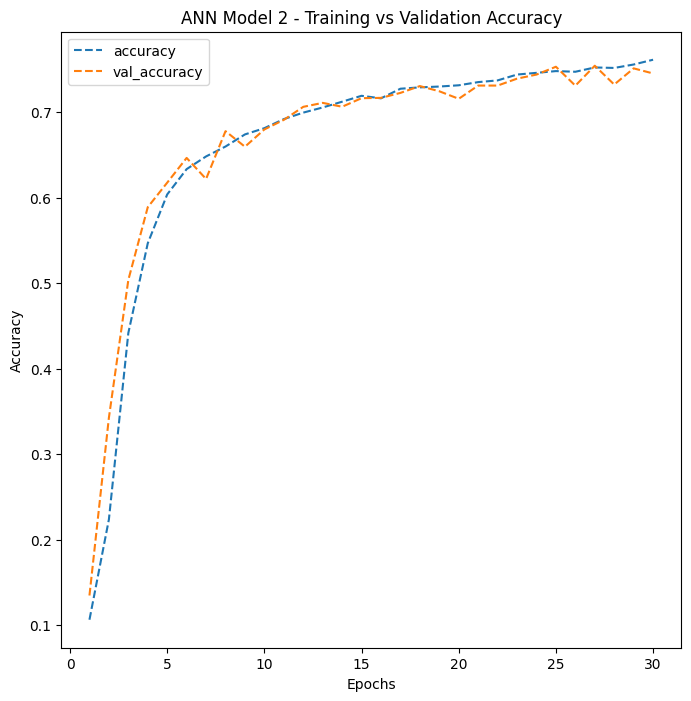 ANN Model 2 shows steady improvement over 30 epochs with a moderate gap between training and validation accuracy – a sign of some overfitting, where the model performs better on training data than on new, unseen data.
ANN Model 2 shows steady improvement over 30 epochs with a moderate gap between training and validation accuracy – a sign of some overfitting, where the model performs better on training data than on new, unseen data.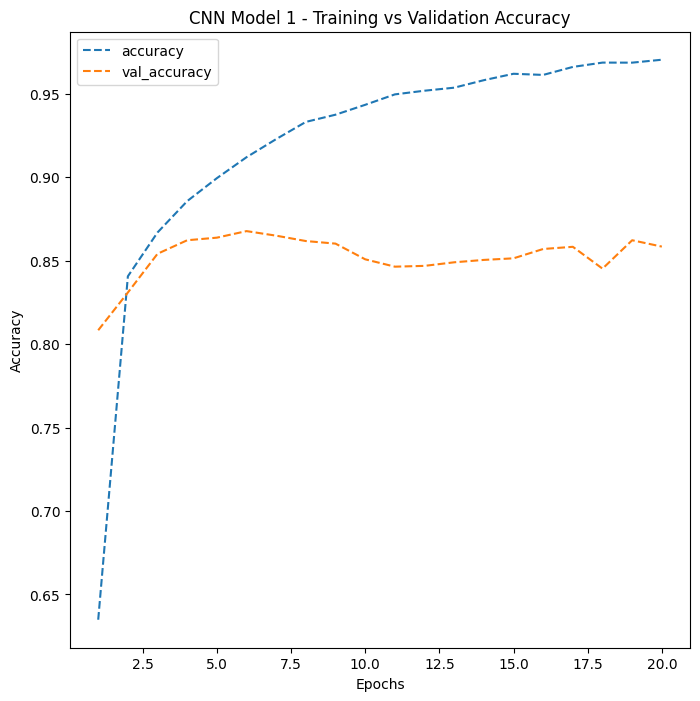 CNN Model 1 demonstrates the dramatic accuracy jump from switching to convolutional architecture. The widening gap between training and validation curves signals overfitting that needs to be addressed.
CNN Model 1 demonstrates the dramatic accuracy jump from switching to convolutional architecture. The widening gap between training and validation curves signals overfitting that needs to be addressed.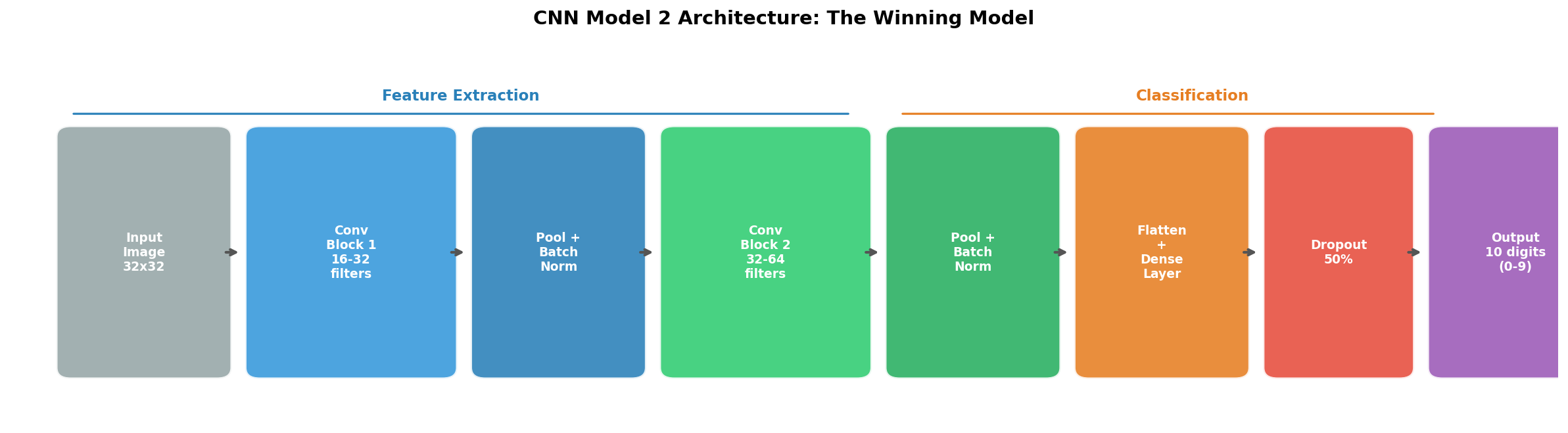 The winning architecture. Convolutional blocks extract increasingly complex visual features, while pooling, Batch Normalization, and Dropout prevent overfitting.
The winning architecture. Convolutional blocks extract increasingly complex visual features, while pooling, Batch Normalization, and Dropout prevent overfitting.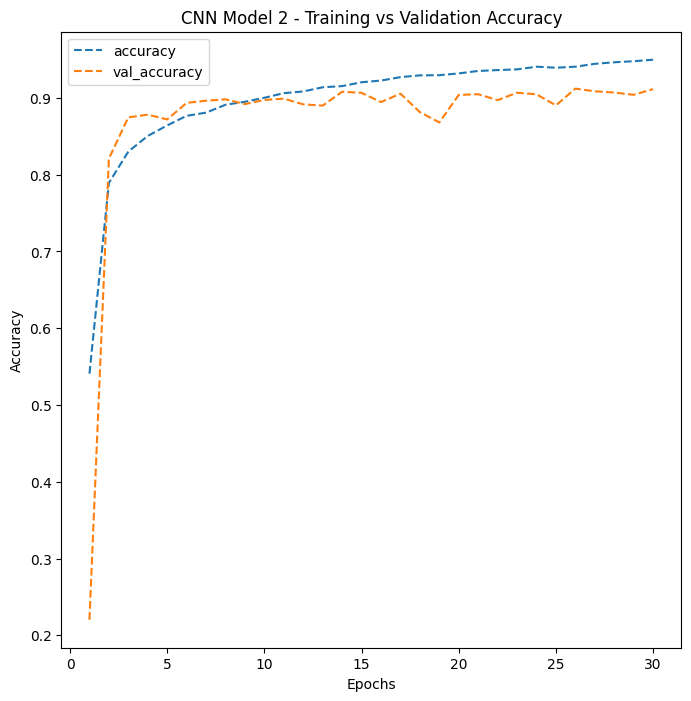 CNN Model 2 shows the tightest gap between training and validation accuracy among all four models – strong evidence of good generalization to unseen data.
CNN Model 2 shows the tightest gap between training and validation accuracy among all four models – strong evidence of good generalization to unseen data. Four models, one dataset, dramatically different results. The 26-percentage-point improvement from the simplest ANN to the best CNN is entirely driven by architectural choices.
Four models, one dataset, dramatically different results. The 26-percentage-point improvement from the simplest ANN to the best CNN is entirely driven by architectural choices.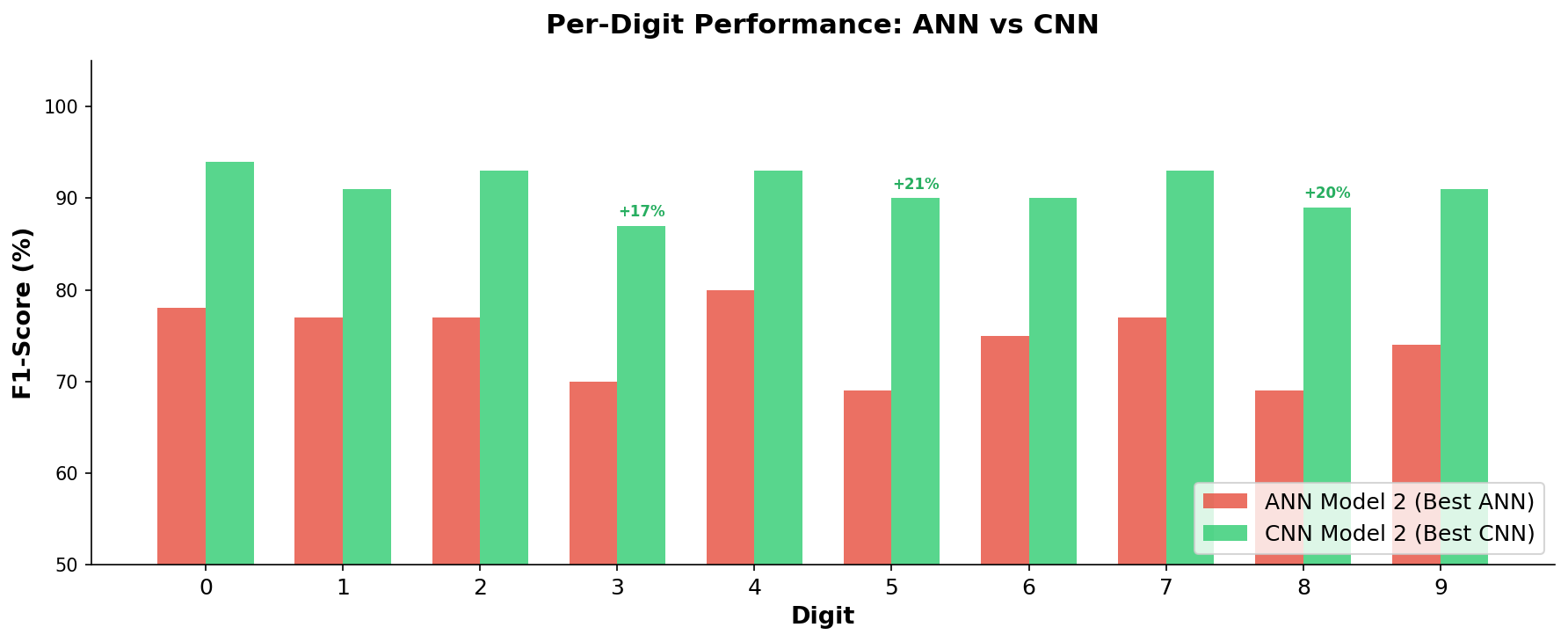 The CNN improves performance on every single digit, but the biggest gains come on the digits that ANNs struggle with most: 3, 5, and 8.
The CNN improves performance on every single digit, but the biggest gains come on the digits that ANNs struggle with most: 3, 5, and 8.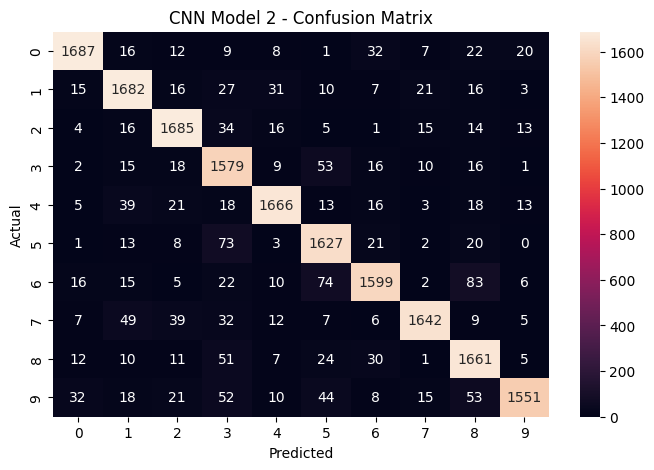 The confusion matrix for the winning CNN model. The strong diagonal (high numbers on the top-left to bottom-right line) shows correct predictions. Off-diagonal entries reveal which digits still get confused – mainly visually similar pairs like 3/8 and 5/6.
The confusion matrix for the winning CNN model. The strong diagonal (high numbers on the top-left to bottom-right line) shows correct predictions. Off-diagonal entries reveal which digits still get confused – mainly visually similar pairs like 3/8 and 5/6.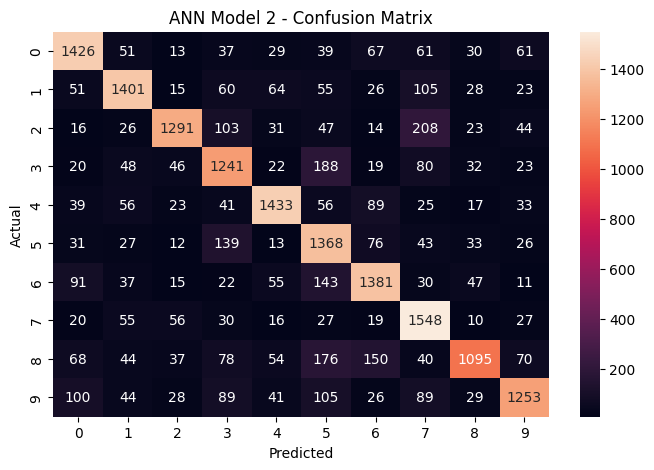 The ANN confusion matrix shows significantly more misclassifications across all digit pairs, with lower values along the diagonal.
The ANN confusion matrix shows significantly more misclassifications across all digit pairs, with lower values along the diagonal.

















