Advancing Network Observability with Custom-Developed Machine Learning Models
Published:
15 min read
Here’s a scenario that will feel painfully familiar to anyone who’s run a network operations center in the last five years.
It’s 2:47 AM. A critical SaaS application starts degrading for users across three regions. The monitoring dashboard lights up — but it lit up after users started complaining. Your on-call engineer begins the investigation, correlating alerts across half a dozen tools. Three hours later, they find the root cause: a subtle BGP routing change by an upstream provider that cascaded into latency spikes across multiple paths.
The data that predicted this failure? It was sitting in your telemetry pipeline the entire time. Nobody — and no thing — was looking at it the right way.
This is the gap that custom-developed machine learning models close. Not generic, off-the-shelf analytics packages that treat every network the same. But models trained specifically on your network’s unique behavior, topology, and traffic patterns. And it’s not theoretical anymore.
The Uncomfortable Truth About Threshold-Based Monitoring
Let’s be honest about something the industry has danced around for too long.
Traditional network monitoring — the kind built on static thresholds — was designed for a world that no longer exists. A world where networks were relatively contained, failure modes were predictable, and an engineer could reasonably hold the full topology in their head.
That world is gone.
Today’s enterprise networks span on-premises data centers, multiple cloud providers, SaaS applications, global WAN links, and millions of endpoints. The combinations of failure modes that can emerge from this complexity are simply too numerous to enumerate in advance.
And yet, most organizations are still running monitoring stacks that operate on a simple principle: “Alert me when metric X crosses threshold Y.”
The problems with this approach are well-documented but worth restating:
- It can only detect problems it was programmed to look for. Novel failure modes — the ones that actually cause the worst outages — slip through entirely.
- Thresholds go stale. A threshold that worked perfectly last quarter may miss a new type of degradation entirely — or flood your team with false positives after a routine infrastructure change.
- It’s reactive by design. By the time a threshold fires, the damage is already happening. Users are already impacted. Revenue is already at risk.
The fundamental limitation isn’t in the tooling. It’s in the paradigm. Threshold-based monitoring tells you when something is already broken. What we need is a system that tells us when something is about to break — and ideally, why.
That’s not a monitoring problem. That’s a machine learning problem.
Why Custom ML Models — and Why Generic Solutions Fall Short
Machine learning isn’t new to IT operations. But here’s the uncomfortable reality: your network is not like anyone else’s network.
Every enterprise network is fundamentally unique — its specific topology, application portfolio, traffic patterns, and operational history create a fingerprint that generic ML models can’t learn. An anomaly detection system tuned for SaaS traffic will generate noise when applied to financial services or manufacturing IoT environments.
This is why custom model development — models trained specifically on your organization’s telemetry — has become the dividing line between ML deployments that deliver transformative value and those that become expensive shelfware.
Three factors make custom ML practical:
1. The data is good enough. ThousandEyes provides structured, normalized, multi-dimensional telemetry across network layers — precisely what ML models need.
2. The models have matured. Autoencoders, Graph Neural Networks, Transformer architectures — production-ready and well-understood.
3. The business case is proven. Organizations deploying custom ML report 60–80% MTTR reductions and 70% fewer false-positive alerts.
Custom models deliver four advantages that generic solutions cannot:
- Pattern recognition tuned to YOUR network — learning your unique topology, application mix, and traffic patterns, flagging deviations that matter in your context
- Continuous adaptability to YOUR changes — retraining on your ongoing telemetry as your environment evolves, no stale thresholds
- Cross-domain correlation for YOUR stack — finding relationships between the systems you actually run, not generic assumptions
- Predictive power aligned with YOUR SLAs — raising alerts 10-30 minutes before service impact, tuned to your performance baselines
ThousandEyes as the Data Foundation
Models are only as good as the data they consume. ThousandEyes provides the ideal foundation for custom ML:
- End-to-end path visibility across internet, cloud, SaaS, and enterprise segments
- Active and passive monitoring via globally distributed agents that proactively test paths
- Cross-layer correlation connecting network events to application outcomes in a single data model
This structured, time-synchronized telemetry makes rapid custom model development possible. The heavy lifting — data collection, normalization, correlation — is already done. Custom models extend ThousandEyes by learning your organization-specific patterns and delivering predictive capabilities.
Think of it this way: ThousandEyes handles “what’s happening.” Custom models add “what’s about to happen” and “why” — tuned to your network’s unique characteristics.
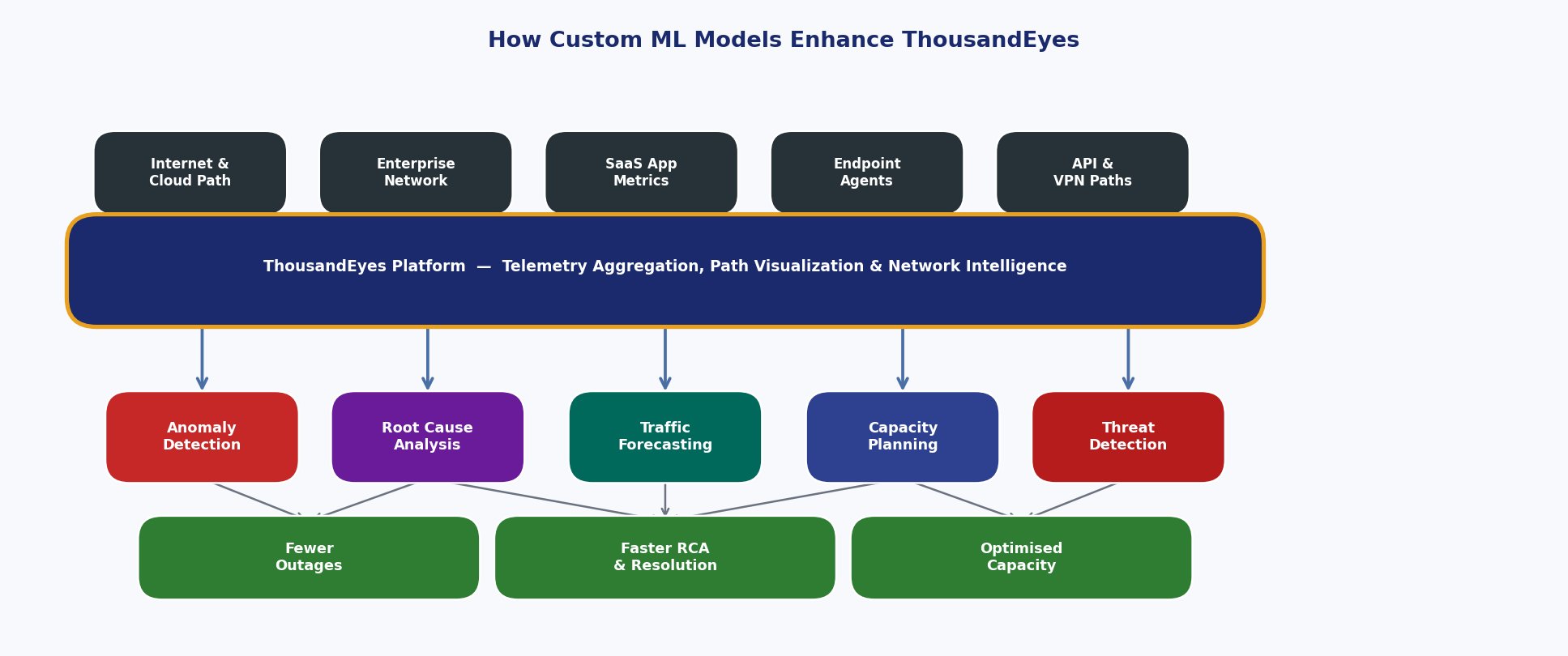
The pipeline shows how ThousandEyes data sources feed custom ML models to deliver actionable business outcomes tailored to your organization.
Why Custom Models Are Non-Negotiable
Why can’t a vendor sell you a pre-trained model that works out of the box?
Because your network has a unique fingerprint that generic models can’t learn:
Unique Topology: Your San Francisco-to-Singapore path routes through specific transit providers with predictable congestion at 18:00 UTC. Your application stack spikes every time the nightly ETL runs. Generic models trained on aggregated industry data never see these patterns.
Unique Applications: A financial services firm’s network during market open looks nothing like a retailer’s during Black Friday. Custom models learn your definition of “busy,” your traffic distribution, your normal failure modes.
Unique SLAs: A 10ms latency increase is noise for a CDN but catastrophic for a trading platform. Custom models learn YOUR thresholds, YOUR priorities, YOUR acceptable trade-offs.
The False Positive Problem: Generic models flag everything statistically unusual because they don’t know your context. Custom models trained on 60–90 days of your telemetry learn what “unusual but normal” means — planned maintenance signatures, expected business-driven traffic spikes, benign infrastructure quirks. Result: 60–80% fewer false positives because the model knows your network’s personality.
Proprietary Systems: Many organizations run custom-built applications or industry-specific infrastructure that doesn’t exist in any vendor’s training dataset. Custom model development is the only path to ML-enhanced observability for these environments.
Real-World Customization: Why Industry Context Matters
Custom models adapt to fundamentally different operational realities. Three examples illustrate the point:
Financial Services: A trading platform needs anomaly detection trained on latency variance, not absolute values — a 2ms spike at 9:29 AM (market open) is catastrophic; the same spike at 3 PM is noise. Custom models learn market hours, understand trading volume patterns, and prioritize specific market data feeds. Generic models can’t distinguish between critical pre-market latency and routine afternoon variation.
E-Commerce/Retail: Seasonal traffic variations (Black Friday, Cyber Monday) would trigger constant false positives in generic anomaly detectors. Custom models learn that Black Friday traffic is expected and instead watch for deviations from the expected Black Friday pattern. Capacity forecasting aligns with promotional calendars and campaign-driven spikes, not industry-average growth curves.
Healthcare/Telehealth: HIPAA compliance constrains what can be logged. Custom models use privacy-preserving feature engineering, learn healthcare operational rhythms (shift changes, morning rounds, appointment patterns), and understand that telehealth video quality thresholds differ from consumer video streaming. Generic models trained on SaaS or retail networks miss the unique signatures of EHR systems and medical imaging transfers.
The pattern: Custom models learn the specific rhythm, priorities, and failure modes of your industry and network — not statistical averages across all networks.
Four Custom Model Applications That Deliver Real Impact
1. Custom Anomaly Detection That Actually Works
Traditional anomaly detection has a credibility problem. Too many false positives have trained operations teams to ignore alerts — which means real problems get buried in noise.
Custom-developed anomaly detection takes a fundamentally different approach. Instead of comparing metrics against static thresholds or using generic pre-trained models, it uses autoencoders trained exclusively on your network’s telemetry — a class of neural network that learns what normal behavior looks like for your specific network, including all its time-of-day patterns, seasonal variations, traffic profiles, and infrastructure-specific quirks.
Think of it like a veteran NOC engineer who has worked your network for years and intuitively knows when something “feels off,” even before they can articulate why. The custom model does the same — it’s trained exclusively on your normal behavior and flags anything it can’t recognize as normal in your context.
The difference between generic and custom models is stark:
A generic anomaly detector might flag your planned nightly backup job as an anomaly because traffic suddenly spikes at 2 AM. A custom model trained on your data knows that pattern is expected and ignores it — while catching the unusual 2 AM spike that indicates a problem.
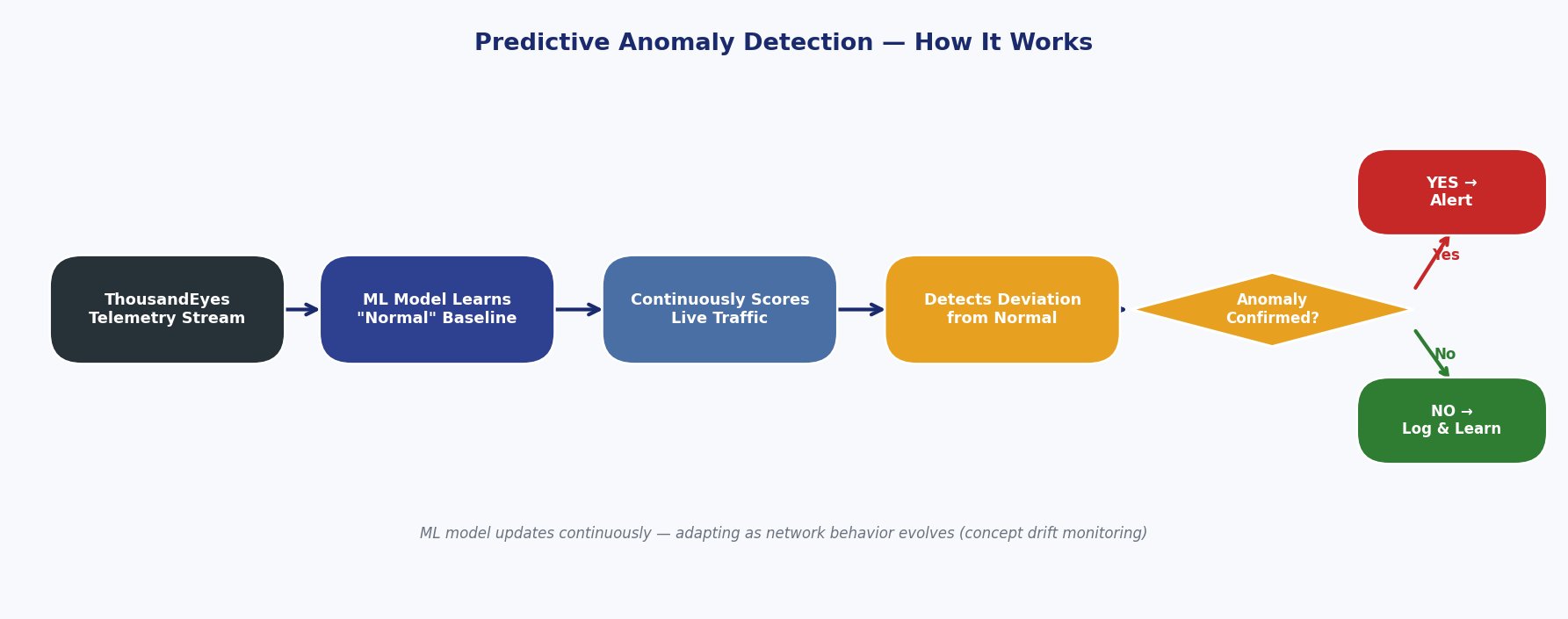
This diagram illustrates the workflow from telemetry collection through baseline learning to real-time anomaly detection and alerting.
The results speak for themselves:
- Catch degradation 10–30 minutes before users notice service impact
- Reduce false-positive alert volume by 60–80% compared to threshold alerting and generic ML
- Detect subtle, multi-metric patterns unique to your topology that no generic solution would surface
ThousandEyes’ path trace data, latency distributions, and BGP event feeds provide the training dataset. The custom model learns what your routing topology normally looks like, what your CDN behavior patterns are, and what changes matter in your environment. Changes that would normally require manual investigation become automatically detectable signals — tailored to your network’s fingerprint.
2. Custom Root Cause Analysis Models
This is where custom ML delivers its most dramatic operational impact.
When a service degrades, the visible symptom — slow application response, packet loss — is rarely the root cause. Something upstream triggered it: a routing change, a link failure, a misconfigured device. Finding that root cause typically involves a “war room” of engineers manually correlating data across multiple tools for hours.
Graph Neural Networks trained on your topology change this equation entirely. By representing your network as a graph — devices as nodes, connections as edges — the custom model learns the dependency relationships between every component in your specific environment. When an alert fires, it propagates the signal back through the graph, computing which upstream events most likely caused the observed downstream effect based on historical patterns it learned from your incident data.
Here’s why customization is critical: Your network’s causal relationships are unique.
In your environment, a specific upstream BGP change might predictably impact certain downstream paths due to your routing policy. A generic model doesn’t know that relationship. A custom model trained on your topology and historical incidents does — it’s learned from every previous failure how problems propagate through your infrastructure.
The output? A ranked list of probable root causes, each with supporting evidence drawn from your network’s historical behavior — delivered in seconds rather than hours.
ThousandEyes’ hop-by-hop path data and BGP routing intelligence give the custom graph model a precise, real-time map of your network’s active topology. The model learns which paths matter most in your environment, which upstream dependencies are critical, and which failure modes you’ve seen before. This makes causal tracing far more accurate than generic approaches based on static network diagrams, CMDB data, or industry-average dependency models.
Impact: MTTR drops from hours to minutes for complex, multi-hop failures — because the model understands your network’s unique failure signatures.
3. Custom Performance Forecasting and Capacity Planning
Over-provisioning wastes money. Under-provisioning causes outages. The traditional approach to capacity planning — a mix of gut feel, historical averages, and generous safety margins — is expensive and unreliable.
Custom time-series forecasting models trained on your historical traffic patterns change this equation. Using Temporal Convolutional Networks or Transformer-based architectures, these models learn your specific demand patterns: business-driven traffic cycles, seasonal variations unique to your industry, growth trends specific to your applications, and the characteristic signatures of your peak usage periods.
A generic forecasting model might predict capacity needs based on industry averages or simple trend extrapolation. A custom model knows that your SaaS application sees predictable traffic spikes every Monday at 9 AM when users return from the weekend, that your e-commerce platform experiences specific seasonal patterns tied to your product launches, and that your video conferencing infrastructure has grown at a specific rate correlated with your headcount expansion.
Custom graph-based models trained on your topology analyze where traffic can be redistributed within your specific infrastructure to improve efficiency — accounting for your routing policies, your multi-cloud architecture, and your business-critical path priorities.
The result: data-driven confidence in capacity decisions tailored to your business context — reducing over-provisioning costs while maintaining the SLA headroom your applications require and preempting congestion events before they impact your users.
4. Custom Security Threat Detection Beyond Signatures
Traditional security tools detect threats that have been seen before and catalogued. The most dangerous attacks — zero-day exploits, novel exfiltration methods, sophisticated lateral movement — are by definition not yet in any signature database.
Custom behavioral detection models trained on your network’s traffic patterns close this gap. By learning the statistical patterns of normal behavior in your specific environment, a custom model flags any significant deviation as potentially suspicious — regardless of whether the specific attack technique has been seen before.
Here’s why the custom approach is essential for security: What’s “normal” in your network is fundamentally different from what’s normal elsewhere.
Your organization has unique traffic flows: specific applications that communicate with specific external services, characteristic usage patterns tied to your business operations, expected data transfer volumes between segments, and normal employee behavior patterns. A custom security model learns these patterns from your data and flags deviations in your context.
Example: A generic model might flag your research team’s legitimate large file transfers to cloud storage as potential exfiltration because the volume is “unusual.” A custom model trained on your data knows this is normal for your organization and ignores it — while flagging the truly anomalous transfer from accounting to an unknown external destination.
What custom behavioral models catch that generic solutions miss:
- DDoS campaigns — anomalous inbound traffic volume and source-IP distribution relative to YOUR baseline
- Data exfiltration — unusual outbound flows to unexpected destinations at unusual times for YOUR organization
- Lateral movement — abnormal inter-segment communication that violates YOUR learned traffic norms and segmentation policies
- Beaconing / C2 communication — distinctive timing patterns in DNS queries or connection intervals that deviate from YOUR normal application behavior
The strongest security posture combines custom ML behavioral detection (which catches the unknown threats unique to your attack surface) with signature-based detection (which catches known threats) — each compensating for the weaknesses of the other, both tuned to your environment.
The Custom Model Development Lifecycle
Five stages from development to production:
1. Data Collection & Feature Engineering: Gather 60–90 days of ThousandEyes telemetry. Network engineers and data scientists identify which paths, metrics, and patterns matter for your SLAs. Feature selection tailored to your business.
2. Model Training & Validation: Train exclusively on your data. The model learns your nightly patterns, predictable congestion signatures, and application-specific latency profiles.
3. Deployment & Integration: Start in “shadow mode” — predictions run but don’t trigger alerts yet. Validate accuracy against actual incidents before transitioning to active alerting.
4. Continuous Monitoring & Drift Detection: Automated tracking detects when “normal” changes. When drift exceeds thresholds, trigger retraining on recent data.
5. Iterative Refinement: Incident retrospectives feed back into training. Every incident resolved makes the model smarter.
The Architecture
The architecture is four layers:
Layer 1 — Data (ThousandEyes). ThousandEyes collects, normalizes, and structures telemetry. Your custom models consume this data.
Layer 2 — Custom ML Models. Specialized models for each task — anomaly detection, root cause analysis, forecasting, security. Each trained exclusively on YOUR data and tuned for your network’s patterns.
Layer 3 — MLOps Orchestration. Monitors model performance, detects concept drift (when “normal” changes), and triggers retraining automatically on your updated data.
Layer 4 — Action. Automated alerts with contextual explanations, operations dashboards, remediation triggers, capacity reports. Engineers receive a diagnosis grounded in your network’s behavior.
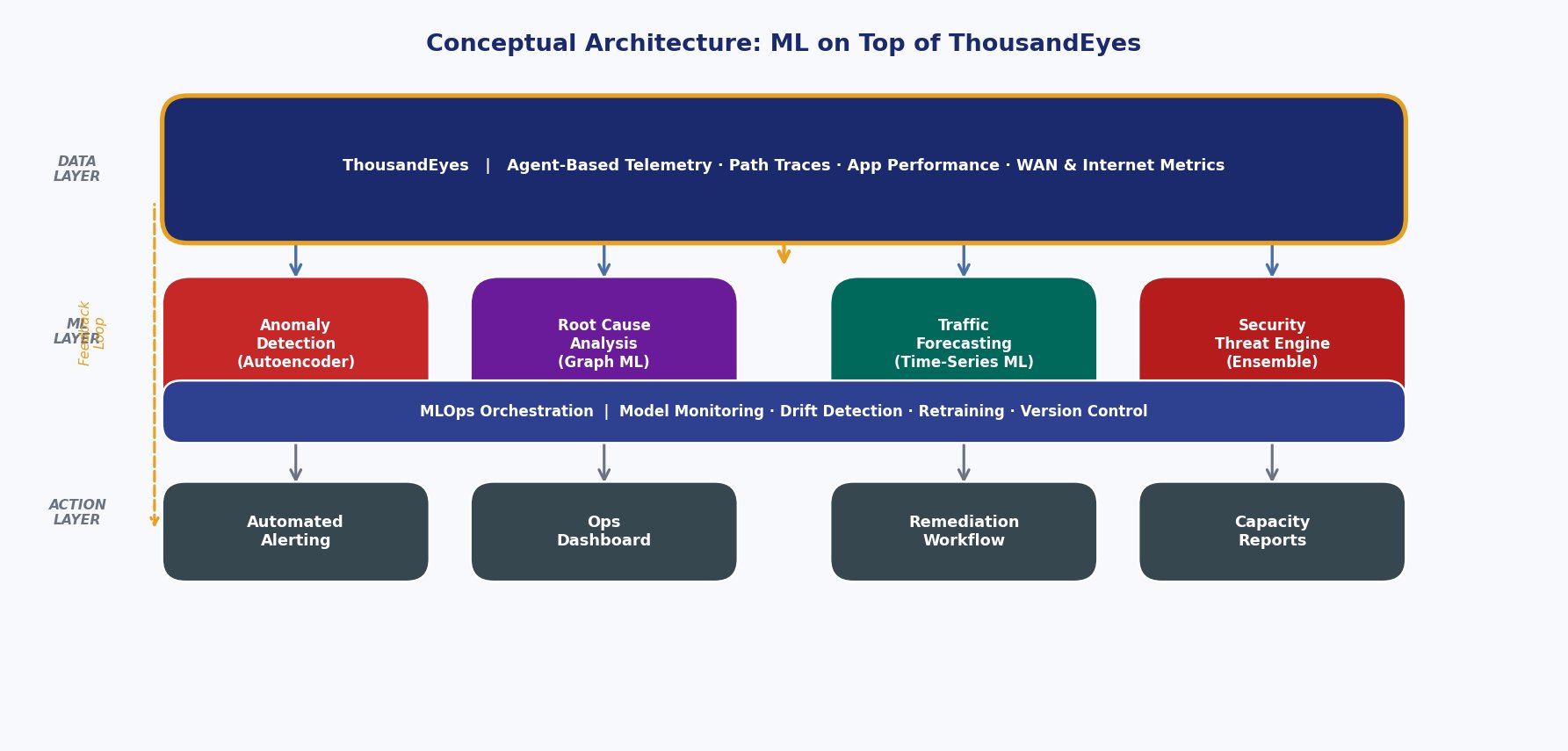
The four-layer architecture showing how ThousandEyes data flows through custom ML models and MLOps orchestration to deliver actionable insights.
Key principle: no single monolithic model. A collection of specialized custom models sharing a common data foundation, modular and continuously refined.
Implementation: Start Small, Scale Smart
Deploying custom ML models doesn’t require a “big bang.” Successful organizations follow a phased approach:
| Phase | Focus | Timeline | Primary Benefit |
|---|---|---|---|
| 1 | Custom anomaly detection on priority paths | 6–10 weeks | Alert fatigue reduction tailored to YOUR traffic |
| 2 | Custom root cause analysis | 10–18 weeks | MTTR reduction based on YOUR topology |
| 3 | Custom traffic forecasting | 14–22 weeks | Spend optimization aligned with YOUR growth |
| 4 | Custom security detection | 18–26 weeks | Zero-day detection tuned to YOUR baseline |
Four critical success factors:
Data quality first. Ensure 60–90 days of clean ThousandEyes telemetry before training. Garbage in, garbage out.
Domain experts + data scientists. Custom model development is a collaboration. ML engineers need operational context; network engineers need data science expertise. Neither succeeds alone.
Model governance from day one. Every model needs a clear owner, performance baseline, retraining policy, and drift detection threshold. Custom models require ongoing stewardship.
Interpretability is non-negotiable. Model outputs must explain why — which metrics, which patterns, what confidence level. Engineers need to validate before acting.
The common pitfall: deploy and forget. Custom models need continuous monitoring and maintenance. Your network evolves; your models must adapt.
The Compounding Effect
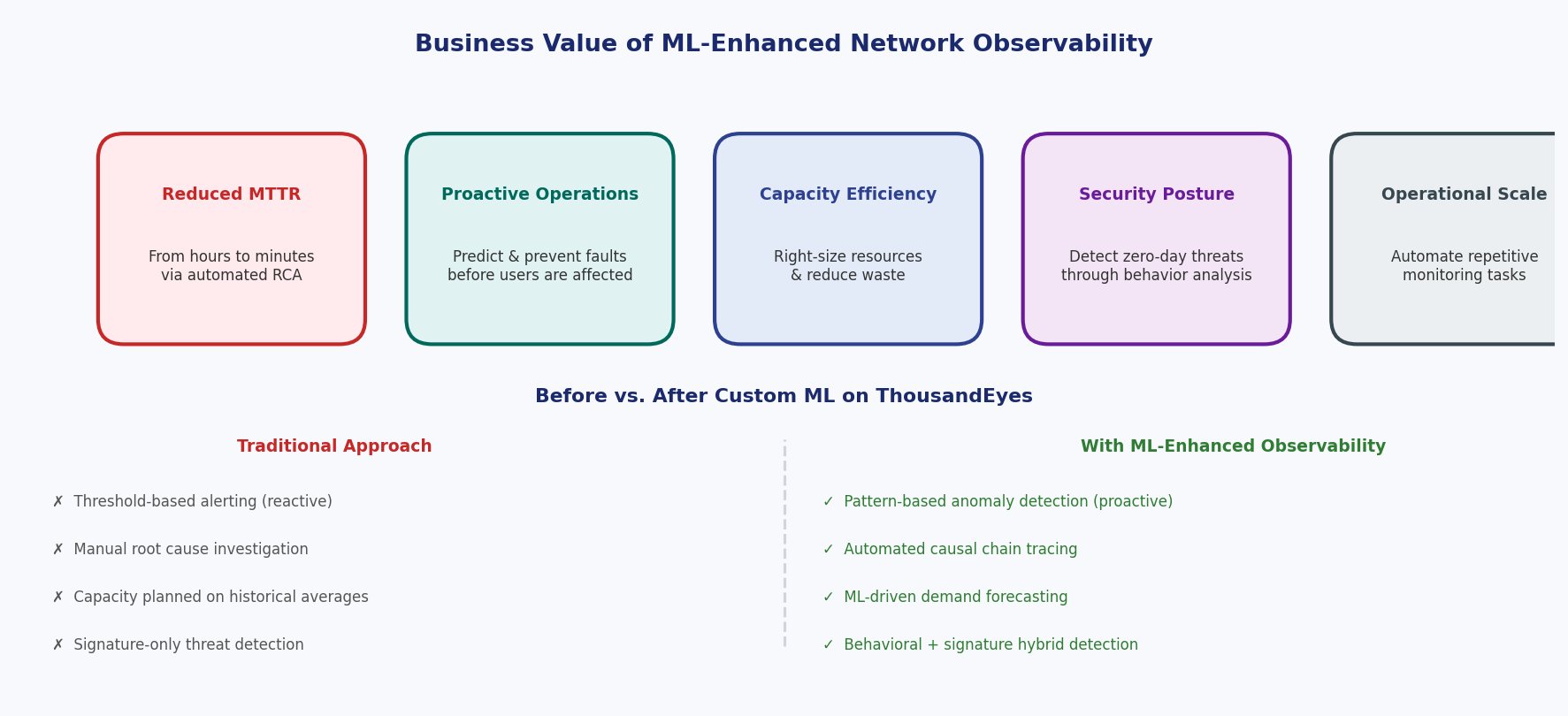
The business value diagram illustrates the tangible benefits and before/after comparison of ML-enhanced network observability.
Each custom model application delivers value independently. But the real power emerges when they work together — all trained on the same organizational data.
Custom traffic forecasts inform capacity decisions. Custom anomaly detection flags deviations from those forecasts. Custom root cause analysis traces problems through your topology referencing your incident history. Custom security models distinguish operational from adversarial deviations using your baseline. Resolution data from each incident feeds back into every model.
Custom models trained on the same organization’s data develop shared context. The anomaly detector knows the same patterns the capacity planner predicts. The root cause analyzer understands the same topology the security model monitors. They speak the language of your network’s behavior.
Every incident resolved, every false positive eliminated makes every custom model more accurate. The models get better at understanding YOUR network specifically — not networks in general. This compounding advantage is nearly impossible to replicate and becomes a sustained competitive moat as models accumulate years of your operational reality.
Where Do We Go From Here?
As networks grow more complex, the limitations of reactive monitoring and generic analytics become strategically untenable.
The technology is ready. The data platforms exist. The business case is proven. The question is whether your organization will be an early mover or a late adopter.
Practical first steps:
- Audit your ThousandEyes deployment. Verify agent coverage and ensure 60–90 days of clean telemetry.
- Identify your unique pain points. Alert fatigue? Unclear root causes? Capacity planning guesswork?
- Scope a Phase 1 pilot on your most critical paths. Define which metrics matter for your environment and what constitutes actionable alerts for your SLAs.
- Set realistic expectations. Custom models take 6–10 weeks for Phase 1 because they include data collection, feature engineering, and training on your data.
Six to ten weeks from now, you’ll have hard data on value — false positive reductions, early warning lead times, incident detection accuracy in your environment. And a foundation to build on.
The strategic insight: The networks that win will be the ones that understand themselves — continuously, predictively, intelligently. That understanding comes from custom models trained on their own operational reality.
Generic ML is better than thresholds. Custom ML is better than generic. The gap is the difference between “this tool flagged an anomaly” and “this model understands our network and told us exactly what’s about to break, why it matters, and what to do.”
References
- Distribution Network Topology Optimization Method Based on Graph Neural Network - ieeexplore.ieee.org
- Graph Deep Learning Meets Persistent Homology - ieeexplore.ieee.org
- Graph Neural Networks from a Graph Signal Processing Perspective: A Concise Overview - ieeexplore.ieee.org
- A Gentle Introduction to Graph Neural Networks - distill.pub
- A Comprehensive Survey on Graph Neural Networks - ieeexplore.ieee.org
- Temporal Convolutional Network — An Overview - medium.com
- Temporal Convolutional Networks and Forecasting - unit8.com
- Temporal Convolutional Network - ScienceDirect - www.sciencedirect.com
[What is TCN? Activeloop Glossary - www.activeloop.ai](https://www.activeloop.ai/resources/glossary/temporal-convolutional-networks-tcn/) - Temporal convolutional networks and data rebalancing for clinical length of stay and mortality prediction - www.nature.com
- Unsupervised anomaly detection with Vision-Transformer and Gaussian Random Field based Variational Autoencoders - arxiv.org
- Research on anomaly detection in attributed networks based on community-aware contrastive adversarial VGAE - link.springer.com
- Novel Feature Extraction on Unsupervised Anomaly Detection for Network Intrusion Packets with Variational Autoencoders - link.springer.com
- Anomaly Detection using a Variational Autoencoder — Part II - medium.com
- SOVAE: An Anomaly Detection System in 5G Network-Based NIDS Using Self-Organizing Map and Variational Autoencoder - www.mdpi.com
- Time-series forecasting with local attention mechanism-based Transformer network - arxiv.org
- Time-series forecasting with local attention mechanism-based Transformer network - arxiv.org
- Deep learning based trajectory and time series forecasting: a review, a comparison, and a look forward - www.sciencedirect.com
- Easy attention: A simple attention mechanism for key-value-query-free and softmax-free transformers with applications to time series and chaotic systems - pubs.aip.org
- Efficient Transformer-based time series forecasting with sparse attention - www.nature.com
- Easy Attention: A Simple Attention Mechanism for Key-Value-Query-Free and Softmax-Free Transformers - arxiv.org
- Attention-based transformer networks predict autonomous vehicle trajectories in the real world - www.nature.com
- ARIMA modeling and forecasting of network traffic based-on GARCH model - link.springer.com
- Time-Varying Network Traffic Prediction using Filtering and ARIMA Model - dl.acm.org
- A Survey of Multivariate Time Series Forecasting Methods on Transportation Networks - www.sciencedirect.com
- Forecasting Internet Network Traffic for the Next new Packets Using ARIMA Model - link.springer.com
- Non-linear Network Traffic Prediction Using Hybrid ARIMA-GARCH Model - link.springer.com
- On the Effectiveness of Data Preprocessing and Hyper-Parameter Optimization for Anomaly Detection in Network Traffic - arxiv.org
- The Reality of Machine Learning in Network Observability - www.kentik.com
- ML-Pipes: An End-to-End Machine Learning Pipeline for Research and Practice - arxiv.org
- Evaluation metrics and statistical tests for machine learning - www.nature.com
- Evaluation metrics and statistical tests for machine learning. - www.researchgate.net
[Model Monitoring Arize ️ - arize.com](https://arize.com/model-monitoring/) - Machine learning model monitoring: Best practices - www.datadoghq.com
- Evaluating Machine Learning Models and Their Diagnostic Value - link.springer.com
- A survey on machine learning-based network anomaly detection - link.springer.com
- Quantum machine learning in cybersecurity: a comprehensive survey - link.springer.com
- Data quality or model selection: which is more important on the performance of ML-based network abnormal and attack detection? - www.mdpi.com
- A Leakage-Resistant Experimental Protocol for Deep Learning-Based Network Traffic Classification - arxiv.org
- Software defined networking based network traffic classification using machine learning techniques - www.nature.com
- Classification of Network Traffic Using Machine Learning Models on the NetML Dataset - aircconline.com
- Network Traffic Classification Using Machine Learning, Transformer, and Large Language Models - arxiv.org
- Evaluation Metrics in Machine Learning - GeeksforGeeks - www.geeksforgeeks.org
- Metrics and scoring: quantifying the quality of predictions - scikit-learn.org
- Predictive Models Performance Evaluation: Which to Choose? - indatalabs.com
- Predictive Model Performance: Offline and Online Evaluations - chbrown.github.io
- A Feature Engineering-Based Survey of Anomaly Detection Techniques - ieeexplore.ieee.org
- Traffic-Explainer: A Model-Agnostic Explanation Framework for Deep Learning-based Network Traffic Classification - arxiv.org
- On the Robustness of Deep Learning-based Network Traffic Classification against Adversarial Perturbations - arxiv.org
- A Survey and Benchmark of Automatic-explaining Methodologies for both Network Traffic Classification and Anomaly Detection - arxiv.org
- A review of performance evaluation metrics for classifiers in cyber-security - www.techscience.com
- An Extensive Review of Feature Selection Metrics for Text Classification - jmlr.csail.mit.edu
- NetBench: A Large-Scale and Comprehensive Network Traffic Benchmark Dataset for Foundation Models - arxiv.org
- CLASSIFICATION OF NETWORK TRAFFIC USING MACHINE LEARNING MODELS ON THE NETML DATASET - www.researchgate.net
- Network traffic verification based on a public dataset for IDS systems and machine learning classification algorithms - ieeexplore.ieee.org
- Network traffic and code for machine learning classification - data.mendeley.com
- Improving Classification Performance for Unbalanced Network Intrusion Detection Data - link.springer.com
- Optimizing Anomaly Detection with ResCAE-BiGRU Hybrid Deep Learning for Imbalanced Network Traffic - www.mdpi.com
- Privacy-Preserving and Accuracy-Improving Framework for Cyber-Attack Classification via Federated Learning in Imbalanced Datasets - www.frontiersin.org
- Leveraging Big Datasets For Machine Learning Based Anomaly Detection In Cybersecurity Network Traffic - www.cmjpublishers.com
- Predictive Model for Detection of Class Imbalance Problem in a Flow-Based Network Intrusion Detection Dataset - link.springer.com
- Cross-validation - ottext.com
- Time-series Cross-validation - www.nixtla.io
- Implementing Time Series Cross Validation to Evaluate the Forecasting Model Performance - www.researchgate.net
- Cross-validation - mlforecast - nixtlaverse.nixtla.io
- Time Series Cross Validation: A Comprehensive Guide - www.analyticsvidhya.com
- Time Series Cross-Validation - GeeksforGeeks - www.geeksforgeeks.org
- What Is Concept Drift in ML and How to Detect It? - evidentlyai.com
- Identifying drift in ML models: Best practices for generating consistent, reliable responses - techcommunity.microsoft.com
- Model Drift in Machine Learning - aerospike.com
- What Is Concept Drift and How to Detect It - Motius - www.motius.com
- Productionizing Machine Learning: From Deployment to Drift Detection - www.databricks.com
- What is Model Drift in ML Systems? A Complete Guide - imerit.ai